
- 首页
- 上一级
- Leaf生成分布式ID的原理?.md
- Redis分布式锁和zk分布式锁哪个对死锁友好_.md
- Redis的分布式锁和Zookeeper的分布式锁有啥区别?.md
- Seata的4种事务模式,各自适合的场景是什么?.md
- Seata的AT模式和XA有什么区别?.md
- Seata的AT模式的实现原理.md
- Seata的实现原理是什么.md
- TCC中,Confirm或者Cancel失败了怎么办?.md
- TCC是强一致性还是最终一致性?.md
- TCC的空回滚和悬挂是什么?如何解决?.md
- 为什么不建议用数据库唯一性约束做幂等控制?.md
- 什么是CAP理论,为什么不能同时满足?.md
- 什么是Canal,他的工作原理是什么?.md
- 什么是TCC,和2PC有什么区别?.md
- 什么是一致性哈希?.md
- 什么是分布式BASE理论?.md
- 什么是分布式事务?.md
- 什么是分布式数据库,有什么优势?.md
- 什么是分布式系统的一致性?.md
- 什么是分布式系统?和集群的区别?.md
- 什么是拜占庭将军问题.md
- 什么是最大努力通知?.md
- 什么是柔性事务?.md
- 什么是负载均衡,有哪些常见算法?.md
- 什么是雪花算法,怎么保证不重复的?.md
- 分布式ID生成方案都有哪些?.md
- 分布式命名方案都有哪些?.md
- 分布式锁有几种实现方式?.md
- 如何基于MQ实现分布式事务.md
- 如何基于本地消息表实现分布式事务?.md
- 如何实现应用中的链路追踪?.md
- 如何解决接口幂等的问题?.md
- 定时任务扫表的缺点有什么?.md
- 实现一个分布式锁需要考虑哪些问题?.md
- 常见的分布式事务有哪些?.md
- 怎么实现分布式Session?.md
- 最大努力通知&事务消息&本地消息表三者区别是什么?.md
- 有了2阶段提交为什么还需要3阶段提交?.md
- 锁和分布式锁的核心区别是什么?.md
✅什么是雪花算法,怎么保证不重复的?
典型回答
雪花算法(Snowflake)是由Twitter研发的一种分布式ID生成算法,它可以生成全局唯一且递增的ID。它的核心思想是将一个64位的ID划分成多个部分,每个部分都有不同的含义,包括时间戳、数据中心标识、机器标识和序列号等。
具体来说,雪花算法生成的ID由以下几个部分组成:
- 符号位(1bit):预留的符号位,始终为0,占用1位。
- 时间戳(41bit):精确到毫秒级别,41位的时间戳可以容纳的毫秒数是2的41次幂,一年所使用的毫秒数是:365 * 24 * 60 * 60 * 1000,算下来可以使用69年。
- 数据中心标识(5bit):可以用来区分不同的数据中心。
- 机器标识(5bit):可以用来区分不同的机器。
- 序列号(12bit):可以生成4096个不同的序列号。

基于以上结构,雪花算法在唯一性保证方面就有很多优势:
首先,时间戳位于ID的最高位,保证新生成的ID比旧的ID大,在不同的毫秒内,时间戳肯定不一样。
其次,引入数据中心标识和机器标识,这两个标识位都是可以手动配置的,帮助业务来保证不同的数据中心和机器能生成不同的ID。
还有就是,引入序列号,用来解决同一毫秒内多次生成ID的问题,每次生成ID时序列号都会自增,因此不同的ID在序列号上有区别。
所以,基于时间戳+数据中心标识+机器标识+序列号,就保证了在不同进程中主键的不重复,在相同进程中主键的有序性。
雪花算法之所以被广泛使用,主要是因为他有以下优点:
- 高性能高可用:生成时不依赖于数据库,完全在内存中生成
- 高吞吐:每秒钟能生成数百万的自增 ID
- ID 自增:在单个进程中,生成的ID是自增的,可以用作数据库主键做范围查询。但是需要注意的是,在集群中是没办法保证一定顺序递增的。
SnowFlake 算法的缺点或者限制:
1、在Snowflake算法中,每个节点的机器ID和数据中心ID都是硬编码在代码中的,而且这些ID是全局唯一的。当某个节点出现故障或者需要扩容时,就需要更改其对应的机器ID或数据中心ID,但是这个过程比较麻烦,需要重新编译代码,重新部署系统。还有就是,如果某个节点的机器ID或数据中心ID被设置成了已经被分配的ID,那么就会出现重复的ID,这样会导致系统的错误和异常。
2、Snowflake算法中,需要使用zookeeper来协调各个节点的ID生成,但是ZK的部署其实是有挺大的成本的,并且zookeeper本身也可能成为系统的瓶颈。
3、依赖于系统时间的一致性,如果系统时间被回拨,或者不一致,可能会造成 ID 重复。
扩展知识
时钟回拨问题
雪花算法使用时间戳作为生成ID的一部分,如果系统时钟回拨,可能会导致生成的ID重复。
时间回拨是指系统在运行过程中,可能由于网络时间校准或者人工设置,导致系统时间主动或被动地跳回到过去的某个时间
一旦发生这种情况,简单粗暴的做法是抛异常,发现时钟回调了,就直接抛异常出来。另外还有一种做法就是发现时钟变小了,就拒绝ID生成请求,等到时钟恢复到上一次的ID生成时间点后,再开始生成新的ID。
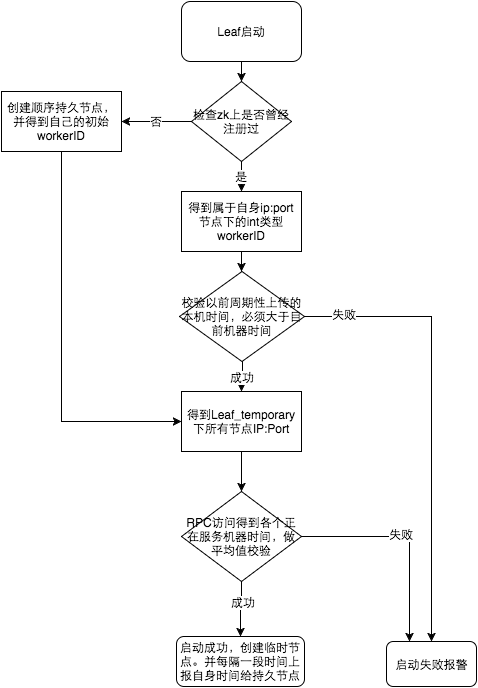
美团 Leaf 引入了 Zookeeper 来解决时钟回拨问题,其大致思路为:每个 Leaf 运行时定时向 zk 上报时间戳。每次 Leaf 服务启动时,先校验本机时间与上次发 ID 的时间,再校验与 zk 上所有节点的平均时间戳。如果任何一个阶段有异常,那么就启动失败报警。
百度的UidGenerator中有两种UidGenerator,其中DefautlUidGenerator使用了System.currentTimeMillis()获取时间与上一次时间比较,当发生时钟回拨时,抛出异常。而CachedUidGenerator使用是放弃了对机器的时间戳的强依赖,而是改用AtomicLong的incrementAndGet()来获取下一次时间,从而脱离了对服务器时间的依赖。