
- 首页
- 上一级
- 40亿个QQ号,限制1G内存,如何去重?.md
- 4C8G_16台和8C16G_8台,不考虑成本的情况怎么选?.md
- 4C8G的机器,各项系统指标,什么范围算是正常?.md
- InnoDB为什么不用跳表,Redis为什么不用B+树?.md
- Kafka,单分区单消费者实例,如何提高吞吐量.md
- MySQL千万级大表如何做数据清理?.md
- MySQL热点数据更新会带来哪些问题?.md
- MySQL里有2000W数据,Redis中只存20W的数据,如何保证Redis中的数据都是热点数据_.md
- Redis如果挂了,你怎么办?.md
- Redis的zset实现排行榜,实现分数相同按照时间顺序排序,怎么做?.md
- Redis的内存如果用满了,会挂吗?.md
- SpringEvent和MQ有什么区别?各自适用场景是什么?.md
- a,b的联合索引,selectbwherea=xx,无法走索引覆盖什么原因?.md
- 一个接口3000QPS,接口RT为200MS,预估需要几台机器?.md
- 一个支付单,多个渠道同时支付成功了怎么办?.md
- 一个表有用户和时间两个列,现有3个需求:根据用户查;根据日期查;根据日期和用户查;问怎么建立索引?.md
- 一个订单,在11_00超时关闭,但在11_00也支付成功了,怎么办?.md
- 一次RPC请求,客户端显示超时,但是服务端不超时,可能是什么原因?.md
- 不使用synchronized和Lock如何设计一个线程安全的单例?.md
- 不用redis分布式锁,如何防止用户重复点击?.md
- 不用大于号小于号怎么判断两个正整数大小?.md
- 为什么MySQL用B+树,MongoDB用B树?.md
- 为什么一定要做限流?不应该服务好客户吗?不应该是加机器吗?.md
- 为什么不建议使用MQ实现订单到期关闭?.md
- 为什么不用分布式锁来实现秒杀?.md
- 为什么不直接用原生的BlockinQueue做消息队列.md
- 为什么很多公司数据库不允许物理删除(delete)数据.md
- 为啥不要在事务中做外部调用?.md
- 从B+树的角度分析为什么单表2000万要考虑分表??.md
- 代码中使用长事务,会带来哪些问题?.md
- 你是如何进行SQL调优的?.md
- 你认为分布式架构一定比单体架构要好吗?.md
- 使用分布式锁时,分布式锁加在事务外面还是里面,有什么区别?.md
- 分布式系统,用户登录信息保存在服务器A上,服务器B如何获取到共享Session.md
- 分库分表时,每个城市的人口不一样,有的密集,有的稀疏,如何实现均匀分布?.md
- 加分布式锁之后影响并发了怎么办?.md
- 和其他公司做数据交互时,有什么需要注意的?.md
- 和外部机构交互如何防止被外部服务不可用而拖垮.md
- 在100M内存下存储一亿个整数,其范围在1到2亿,如何快速判断给定到一个整数值是否存在?.md
- 外卖系统,一天一千万条数据,用户需要查到近30天的数据,商家也要查询到30天的数据,怎么设计表?.md
- 大型电商的订单系统,如何设计分库分表方案?.md
- 大量的手机号码被标记成骚扰电话,如何存储这些号码_.md
- 如何做SQL调优:用了主键索引反而查询很慢?.md
- 如何做平滑的数据迁移_.md
- 如何实现_查找附近的人_功能?.md
- 如何实现一个抢红包功能?.md
- 如何实现敏感词过滤?.md
- 如何实现百万级排行榜功能?.md
- 如何实现百万级数据从Excel导入到数据库?.md
- 如何实现缓存的预热?.md
- 如何用Redis实现朋友圈点赞功能?.md
- 如何解决消息重复消费、重复下单等问题?.md
- 如何设计一个购物车功能?.md
- 如何预估一个系统的QPS?.md
- 如果你的业务量突然提升100倍QPS你会怎么做?.md
- 如果单表数据量大,只能考虑分库分表吗?.md
- 如果要存IP地址,用什么数据类型比较好?.md
- 如果让你实现一个RPC框架,会考虑用哪些技术解决哪些问题?.md
- 如果让你实现消息队列,会考虑哪些问题?.md
- 如果需要跨库join,该如何实现?.md
- 实现一个登录拉黑功能,实现拉黑用户和把已经登陆用户踢下线。.md
- 库存扣减如何避免超卖和少卖?.md
- 应用占用内存持续增长,但是堆内存、元空间都没变化,可能是什么原因?.md
- 应用启动后前几分钟,Load、RT、CPU等飙高,如何定位,可能的原因是什么?.md
- 怎么做数据对账?.md
- 把商品加入购物车时断网了,该怎么在重新联网时同步?.md
- 数据库乐观锁和悲观锁以及redis分布式锁的区别和使用场景?.md
- 数据库逻辑删除后,怎么做唯一性约束?.md
- 每天100w次登录请求,4C8G机器如何做JVM调优?.md
- 消息队列使用拉模式好还是推模式好?为什么?.md
- 用了一锁二查三更新,为啥还出现了重复数据?.md
- 电商下单场景,如何设计一个数据一致性方案?.md
- 索引失效的问题是如何排查的,有那些种情况?.md
- 线上接口如果响应很慢如何去排查定位问题呢?.md
- 给第三方提供接口调用,需要注意些什么?.md
- 订单到期关闭如何实现.md
- 让你设计一个秒杀系统,你会考虑哪些问题?.md
- 让你设计一个订单号生成服务,该怎么做_.md
- 说一说多级缓存是如何应用的?.md
- 读取一千个文件,一个线程读取和开十个线程读取,哪种方式效率高?.md
- 调用第三方接口支付时,第三方接口显示支付成功,但是在调用方显示支付失败,问题可能出在哪里.md
- 进入电梯里断网后又恢复刚开始为什么网络慢?.md
- 项目中,如果日志打印成为瓶颈,该如何优化?.md
- 高并发的库存系统,在数据库扣减库存,怎么实现?.md
✅在100M内存下存储一亿个整数,其范围在1到2亿,如何快速判断给定到一个整数值是否存在?
典型回答
这是一个比较典型的海量数据处理的问题,在优先内存情况下进行数据排序、判断是否存在等。
主要考察面试者对大数据量计算的经验和思考方式。同时也考察面试者是否有对一些数据库、数据处理中间件原理有过深入的了解。
一般来说有以下几个方案:
方案一(内存不够)
使用Java的list、hashSet提供的方法:list.contains() 、set.contains()
时间复杂度分析:
- list的contains方法底层是通过遍历整个list,挨个元素进行比对,找出期望值,其时间复杂度为O(n)
- hashSet底层本质是个hashMap,在进行add时,将值存入hashMap的key中,contains时对值进行hash后查找,其时间复杂度为O(1)
内存空间占用分析:
- 整数范围在Integer.MAX_VALUE之内,占4个字节
- list和set都要存储所有元素
- list的空间计算:100,000,000(整数数量) × 4(字节 / 整数) = 400,000,000(字节)
需要注意的是,这只是粗略的估计。实际的内存占用可能会受到 Java 虚拟机的优化和内存管理策略的影响。此外,还要考虑 List 对象本身的内存开销,以及其他可能的因素(如对象引用、空间对齐等)对内存占用的影响。因此,实际内存占用可能会略高于这个估算值。
hashSet的空间计算:100,000,000(整数数量) × 8(字节 / 整数) = 800,000,000(字节)
由于 hashSet 使用了hashMap数据结构,还需要考虑额外的内存开销用于存储散列桶、链表或红黑树等信息。这个开销通常是每个元素 3~4 倍左右,取决于具体实现和负载因子等因素。 假设每个元素的额外开销为 2 倍,那么每个整数占用的内存空间为:4 字节 × 2 = 8 字节。
显然时间复杂度只有hashSet能胜任,对于内存空间早已超出给定的100M限制。
方案2(可行)
使用bitmap算法降低内存空间,且时间复杂度为O(1)
java.util.BitSet是java中bitmap算法的实现,可以初始化一个2亿的BitSet,并把1到2亿通过bitSet.set()方法设置进去,并通过bitSet.get()方法判断期望值是否存在。
内存空间占用分析:2,0000,0000(位) ÷ 8(位 / 字节) ÷ 1024(字节 / KB) ÷ 1024(KB/MB) ≈ 23.84 MB
显然bitmap在时间复杂度和空间占用上都完全满足需求。
扩展知识
上述方案2中,存在一个问题:我们要初始化2个亿的bit数组去承载1个亿的数据需求,有点高射炮打蚊子的感觉。
工作中我们并不能百分之百确定一个长期运营的产品用户产生的数据量有多大,同时业务需求也不会只是在海量数据里找出一个值那么简单。通常会有如下几个场景:
- 用户画像系统:用户行为数据、基础数据等信息散落在不同数据库中(ES、MySQL、Doris等)。去不同数据库中查数据,然后通过long类型的uid灌入bitMap,求交集、并集、差集,找出满足复杂查询条件的用户。
- 推荐系统中,精准记录某个用户是否已读。为每个用户分配一个bitMap,将已读的文章id放入bitMap中,已读过不再进行推荐。
上面的3个业务场景中,在使用bitMap除了要初始化一个较大的数组外,还存在一个致命的硬伤:由于id为稀疏整数,会浪费内存空间,效率非常低。
稀疏整数,即向bitMap的数组中存放不连续的整数,如:1,50001,20,910321。如果这四个数字使用bitMap存储,我们要初始化至少910321个bit数组元素,只有这四个位为1,其他位为0,空间被白白浪费。
解决这种问题的一个很好的思路是,尝试对数据集中的整数进行压缩,比如将32位整数拆分成高16位和低16位,将高16位相同的数字放在一起(一个container),低16位形成一个bitmap(本质上也是个bit数组可称作bucket)。
可以简单理解成一个hashmap下挂了bitmap,这样对32位整形进一步压缩。对于稀疏的数据集,大幅度降低内存占用。
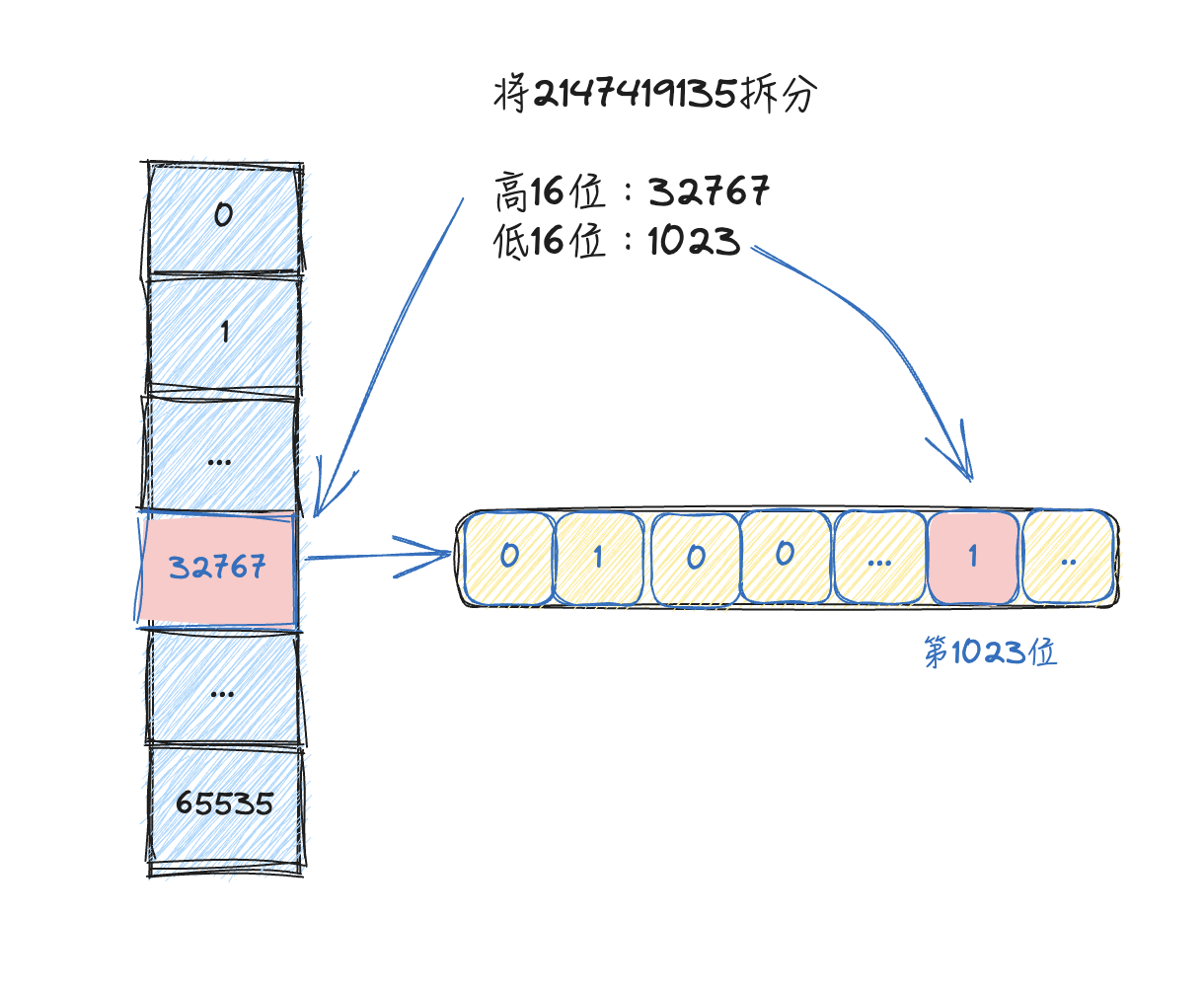
这样的基本思路已经有了现成的实现,即RoaringBitmap,其开源实现不止局限于java,也有C++、go等多种语言。官网地址:https://roaringbitmap.org。
他主要有以下优点:
- 支持32位和64位数据集的聚合运算
- 位运算速度非常快,基本都是O(1)时间复杂度,且内部实现大多使用数组,对CPU L1缓存非常友好
- 便捷的使用方式,与
java.lang.BitSet接口相同,简单明了,同时功能比BitSet多 - 具有强大的社区,ElasticSearch、kylin、Hive、InfluxDB都用了这套算法,开源社区也很活跃
- 提供多种container,针对运行时的数据量级、稀疏程度自动平衡转换
当然,他也有缺点:
每个container算法实现不同,如果想深入钻进去看源码或官方的论文,还是比较难理解的。