
- 首页
- 上一级
- 40亿个QQ号,限制1G内存,如何去重?.md
- 4C8G_16台和8C16G_8台,不考虑成本的情况怎么选?.md
- 4C8G的机器,各项系统指标,什么范围算是正常?.md
- InnoDB为什么不用跳表,Redis为什么不用B+树?.md
- Kafka,单分区单消费者实例,如何提高吞吐量.md
- MySQL千万级大表如何做数据清理?.md
- MySQL热点数据更新会带来哪些问题?.md
- MySQL里有2000W数据,Redis中只存20W的数据,如何保证Redis中的数据都是热点数据_.md
- Redis如果挂了,你怎么办?.md
- Redis的zset实现排行榜,实现分数相同按照时间顺序排序,怎么做?.md
- Redis的内存如果用满了,会挂吗?.md
- SpringEvent和MQ有什么区别?各自适用场景是什么?.md
- a,b的联合索引,selectbwherea=xx,无法走索引覆盖什么原因?.md
- 一个接口3000QPS,接口RT为200MS,预估需要几台机器?.md
- 一个支付单,多个渠道同时支付成功了怎么办?.md
- 一个表有用户和时间两个列,现有3个需求:根据用户查;根据日期查;根据日期和用户查;问怎么建立索引?.md
- 一个订单,在11_00超时关闭,但在11_00也支付成功了,怎么办?.md
- 一次RPC请求,客户端显示超时,但是服务端不超时,可能是什么原因?.md
- 不使用synchronized和Lock如何设计一个线程安全的单例?.md
- 不用redis分布式锁,如何防止用户重复点击?.md
- 不用大于号小于号怎么判断两个正整数大小?.md
- 为什么MySQL用B+树,MongoDB用B树?.md
- 为什么一定要做限流?不应该服务好客户吗?不应该是加机器吗?.md
- 为什么不建议使用MQ实现订单到期关闭?.md
- 为什么不用分布式锁来实现秒杀?.md
- 为什么不直接用原生的BlockinQueue做消息队列.md
- 为什么很多公司数据库不允许物理删除(delete)数据.md
- 为啥不要在事务中做外部调用?.md
- 从B+树的角度分析为什么单表2000万要考虑分表??.md
- 代码中使用长事务,会带来哪些问题?.md
- 你是如何进行SQL调优的?.md
- 你认为分布式架构一定比单体架构要好吗?.md
- 使用分布式锁时,分布式锁加在事务外面还是里面,有什么区别?.md
- 分布式系统,用户登录信息保存在服务器A上,服务器B如何获取到共享Session.md
- 分库分表时,每个城市的人口不一样,有的密集,有的稀疏,如何实现均匀分布?.md
- 加分布式锁之后影响并发了怎么办?.md
- 和其他公司做数据交互时,有什么需要注意的?.md
- 和外部机构交互如何防止被外部服务不可用而拖垮.md
- 在100M内存下存储一亿个整数,其范围在1到2亿,如何快速判断给定到一个整数值是否存在?.md
- 外卖系统,一天一千万条数据,用户需要查到近30天的数据,商家也要查询到30天的数据,怎么设计表?.md
- 大型电商的订单系统,如何设计分库分表方案?.md
- 大量的手机号码被标记成骚扰电话,如何存储这些号码_.md
- 如何做SQL调优:用了主键索引反而查询很慢?.md
- 如何做平滑的数据迁移_.md
- 如何实现_查找附近的人_功能?.md
- 如何实现一个抢红包功能?.md
- 如何实现敏感词过滤?.md
- 如何实现百万级排行榜功能?.md
- 如何实现百万级数据从Excel导入到数据库?.md
- 如何实现缓存的预热?.md
- 如何用Redis实现朋友圈点赞功能?.md
- 如何解决消息重复消费、重复下单等问题?.md
- 如何设计一个购物车功能?.md
- 如何预估一个系统的QPS?.md
- 如果你的业务量突然提升100倍QPS你会怎么做?.md
- 如果单表数据量大,只能考虑分库分表吗?.md
- 如果要存IP地址,用什么数据类型比较好?.md
- 如果让你实现一个RPC框架,会考虑用哪些技术解决哪些问题?.md
- 如果让你实现消息队列,会考虑哪些问题?.md
- 如果需要跨库join,该如何实现?.md
- 实现一个登录拉黑功能,实现拉黑用户和把已经登陆用户踢下线。.md
- 库存扣减如何避免超卖和少卖?.md
- 应用占用内存持续增长,但是堆内存、元空间都没变化,可能是什么原因?.md
- 应用启动后前几分钟,Load、RT、CPU等飙高,如何定位,可能的原因是什么?.md
- 怎么做数据对账?.md
- 把商品加入购物车时断网了,该怎么在重新联网时同步?.md
- 数据库乐观锁和悲观锁以及redis分布式锁的区别和使用场景?.md
- 数据库逻辑删除后,怎么做唯一性约束?.md
- 每天100w次登录请求,4C8G机器如何做JVM调优?.md
- 消息队列使用拉模式好还是推模式好?为什么?.md
- 用了一锁二查三更新,为啥还出现了重复数据?.md
- 电商下单场景,如何设计一个数据一致性方案?.md
- 索引失效的问题是如何排查的,有那些种情况?.md
- 线上接口如果响应很慢如何去排查定位问题呢?.md
- 给第三方提供接口调用,需要注意些什么?.md
- 订单到期关闭如何实现.md
- 让你设计一个秒杀系统,你会考虑哪些问题?.md
- 让你设计一个订单号生成服务,该怎么做_.md
- 说一说多级缓存是如何应用的?.md
- 读取一千个文件,一个线程读取和开十个线程读取,哪种方式效率高?.md
- 调用第三方接口支付时,第三方接口显示支付成功,但是在调用方显示支付失败,问题可能出在哪里.md
- 进入电梯里断网后又恢复刚开始为什么网络慢?.md
- 项目中,如果日志打印成为瓶颈,该如何优化?.md
- 高并发的库存系统,在数据库扣减库存,怎么实现?.md
✅外卖系统,一天一千万条数据,用户需要查到近30天的数据,商家也要查询到30天的数据,怎么设计表?
典型回答
分析一下题干的几个关键信息:
1、一天一千万数据。
2、只查最近30天的数据
3、买家和商家都需要查询
通过以上三个信息,我们可以得出以下结论:
1、单表扛不住:
1天就1000万数据,一年就30多亿数据,那么这个量如果用一张单表存放的话,数据库肯定扛不住。
2、可以做数据归档
因为用户只查询最近30天的数据,所以,可以简单的按照时间来划分冷热数据,30天内的数据为热数据,30天以外的数据为冷数据。冷数据和热数据可以做分离,即针对30天以上的数据做归档。
3、归档后单表还是扛不住
但是,归档之后,热数据的表还要保留30的数据,也就是3个亿,那还是很多的,单靠数据库也扛不住。需要考虑做分库分表
4、分表键不能直接选择买家或者卖家
因为要同时满足买家和卖家的查询,不可能只基于买家或者卖家去做分表。如果按照卖家 id 分表,那么买家的查询就会跨表,查询很慢。按照买家 id 分表也是同理。
5、基本不太可能使用缓存提效
这个很好理解,一方面是数据量太大了,另外一方面订单信息可能会频繁修改,数据一致性不太好保障,这里用缓存不合适。
那么,这个问题最终就变成了一个,如何基于海量数据(3亿)数据走高效查询,并且要支持多个分表键。
分布式数据库
首先,我们可以用支持海量数据存储和查询的各种分布式是数据库,如TiDB(pingcap)、OceanBase(蚂蚁)、Spanner(google)等。
用了分布式数据库之后,为了提升买家和卖家的查询效率,需要分别创建索引:
CREATE TABLE Orders (
order_id BIGINT AUTO_INCREMENT PRIMARY KEY,
buyer_id BIGINT NOT NULL,
seller_id BIGINT NOT NULL,
order_date DATETIME NOT NULL,
amout DECIMAL(10, 2),
status ENUM('Pending', 'Completed', 'Cancelled', 'Refunded'),
INDEX idx_buyer_date (buyer_id, order_date),
INDEX idx_seller_date (seller_id, order_date)
);
创建买家ID+时间、卖家 ID+时间等多个联合索引,来提升按照时间查询的效率。
分库分表
除了分布式数据库,还可以用分库分表的方案,在分库分表中我们介绍过,按照买家 ID 分表后,卖家的查询怎么办问题。
也就是说,我们在做了数据归档之后(一般是先分表之后然后再归档,但是不重要,你知道需要归档即可。),针对最近30填的数据,可以按照买家 ID进行分表,这么大的量 ,建议分成64张表,这样平均下来,单张表就大概有1000万 * 30 / 32不到一千万条数据了。这时候按照买家 ID 的查询就很高效了。
之所以按照买家 ID 先做分表,就是为了避免数据倾斜。建表语句如下:
CREATE TABLE orders (
order_id BIGINT AUTO_INCREMENT PRIMARY KEY,
buyer_id BIGINT NOT NULL,
seller_id BIGINT NOT NULL,
order_date DATETIME NOT NULL,
amout DECIMAL(10, 2),
status ENUM('Pending', 'Completed', 'Cancelled', 'Refunded'),
INDEX idx_user_date (buyer_id, order_date)
);
这样就解决了买家的查询效率问题,那么卖家的查询呢,我们可以采用数据同步的方案,利用空间换时间的方案,将数据冗余一份,再以卖家 ID 做分表:
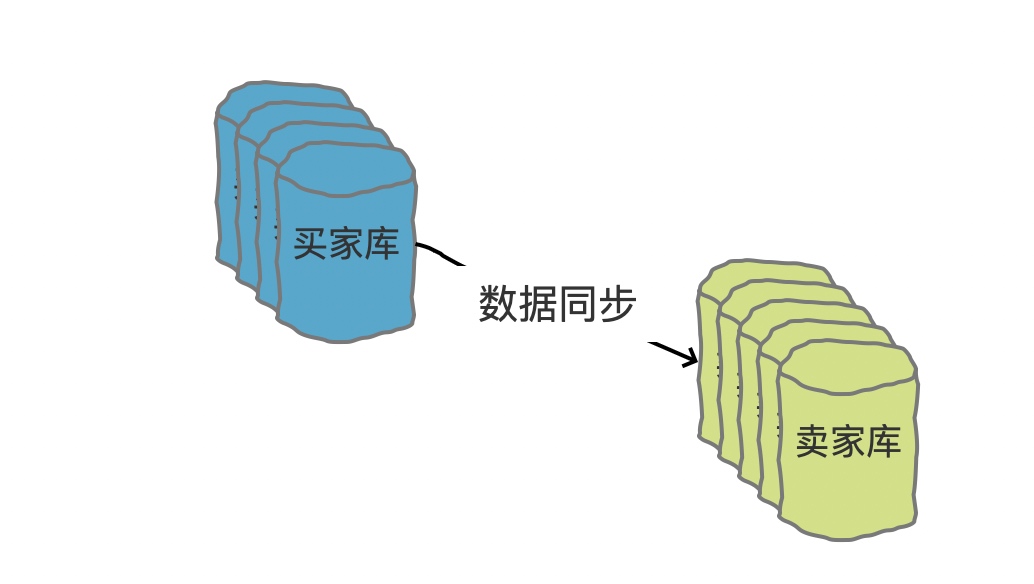
CREATE TABLE orders_seller (
order_id BIGINT AUTO_INCREMENT PRIMARY KEY,
buyer_id BIGINT NOT NULL,
seller_id BIGINT NOT NULL,
order_date DATETIME NOT NULL,
amout DECIMAL(10, 2),
status ENUM('Pending', 'Completed', 'Cancelled', 'Refunded'),
INDEX idx_seller_date (seller_id, order_date)
);
我们说同步一张卖家维度的表来,但是其实所有的写操作还是要写到买家表的,只不过需要准实时同步的方案同步到卖家表中。也就是说,我们的这个卖家表理论上是没有业务的写操作,只有读操作的。