
- 首页
- 上一级
- 40亿个QQ号,限制1G内存,如何去重?.md
- 4C8G_16台和8C16G_8台,不考虑成本的情况怎么选?.md
- 4C8G的机器,各项系统指标,什么范围算是正常?.md
- InnoDB为什么不用跳表,Redis为什么不用B+树?.md
- Kafka,单分区单消费者实例,如何提高吞吐量.md
- MySQL千万级大表如何做数据清理?.md
- MySQL热点数据更新会带来哪些问题?.md
- MySQL里有2000W数据,Redis中只存20W的数据,如何保证Redis中的数据都是热点数据_.md
- Redis如果挂了,你怎么办?.md
- Redis的zset实现排行榜,实现分数相同按照时间顺序排序,怎么做?.md
- Redis的内存如果用满了,会挂吗?.md
- SpringEvent和MQ有什么区别?各自适用场景是什么?.md
- a,b的联合索引,selectbwherea=xx,无法走索引覆盖什么原因?.md
- 一个接口3000QPS,接口RT为200MS,预估需要几台机器?.md
- 一个支付单,多个渠道同时支付成功了怎么办?.md
- 一个表有用户和时间两个列,现有3个需求:根据用户查;根据日期查;根据日期和用户查;问怎么建立索引?.md
- 一个订单,在11_00超时关闭,但在11_00也支付成功了,怎么办?.md
- 一次RPC请求,客户端显示超时,但是服务端不超时,可能是什么原因?.md
- 不使用synchronized和Lock如何设计一个线程安全的单例?.md
- 不用redis分布式锁,如何防止用户重复点击?.md
- 不用大于号小于号怎么判断两个正整数大小?.md
- 为什么MySQL用B+树,MongoDB用B树?.md
- 为什么一定要做限流?不应该服务好客户吗?不应该是加机器吗?.md
- 为什么不建议使用MQ实现订单到期关闭?.md
- 为什么不用分布式锁来实现秒杀?.md
- 为什么不直接用原生的BlockinQueue做消息队列.md
- 为什么很多公司数据库不允许物理删除(delete)数据.md
- 为啥不要在事务中做外部调用?.md
- 从B+树的角度分析为什么单表2000万要考虑分表??.md
- 代码中使用长事务,会带来哪些问题?.md
- 你是如何进行SQL调优的?.md
- 你认为分布式架构一定比单体架构要好吗?.md
- 使用分布式锁时,分布式锁加在事务外面还是里面,有什么区别?.md
- 分布式系统,用户登录信息保存在服务器A上,服务器B如何获取到共享Session.md
- 分库分表时,每个城市的人口不一样,有的密集,有的稀疏,如何实现均匀分布?.md
- 加分布式锁之后影响并发了怎么办?.md
- 和其他公司做数据交互时,有什么需要注意的?.md
- 和外部机构交互如何防止被外部服务不可用而拖垮.md
- 在100M内存下存储一亿个整数,其范围在1到2亿,如何快速判断给定到一个整数值是否存在?.md
- 外卖系统,一天一千万条数据,用户需要查到近30天的数据,商家也要查询到30天的数据,怎么设计表?.md
- 大型电商的订单系统,如何设计分库分表方案?.md
- 大量的手机号码被标记成骚扰电话,如何存储这些号码_.md
- 如何做SQL调优:用了主键索引反而查询很慢?.md
- 如何做平滑的数据迁移_.md
- 如何实现_查找附近的人_功能?.md
- 如何实现一个抢红包功能?.md
- 如何实现敏感词过滤?.md
- 如何实现百万级排行榜功能?.md
- 如何实现百万级数据从Excel导入到数据库?.md
- 如何实现缓存的预热?.md
- 如何用Redis实现朋友圈点赞功能?.md
- 如何解决消息重复消费、重复下单等问题?.md
- 如何设计一个购物车功能?.md
- 如何预估一个系统的QPS?.md
- 如果你的业务量突然提升100倍QPS你会怎么做?.md
- 如果单表数据量大,只能考虑分库分表吗?.md
- 如果要存IP地址,用什么数据类型比较好?.md
- 如果让你实现一个RPC框架,会考虑用哪些技术解决哪些问题?.md
- 如果让你实现消息队列,会考虑哪些问题?.md
- 如果需要跨库join,该如何实现?.md
- 实现一个登录拉黑功能,实现拉黑用户和把已经登陆用户踢下线。.md
- 库存扣减如何避免超卖和少卖?.md
- 应用占用内存持续增长,但是堆内存、元空间都没变化,可能是什么原因?.md
- 应用启动后前几分钟,Load、RT、CPU等飙高,如何定位,可能的原因是什么?.md
- 怎么做数据对账?.md
- 把商品加入购物车时断网了,该怎么在重新联网时同步?.md
- 数据库乐观锁和悲观锁以及redis分布式锁的区别和使用场景?.md
- 数据库逻辑删除后,怎么做唯一性约束?.md
- 每天100w次登录请求,4C8G机器如何做JVM调优?.md
- 消息队列使用拉模式好还是推模式好?为什么?.md
- 用了一锁二查三更新,为啥还出现了重复数据?.md
- 电商下单场景,如何设计一个数据一致性方案?.md
- 索引失效的问题是如何排查的,有那些种情况?.md
- 线上接口如果响应很慢如何去排查定位问题呢?.md
- 给第三方提供接口调用,需要注意些什么?.md
- 订单到期关闭如何实现.md
- 让你设计一个秒杀系统,你会考虑哪些问题?.md
- 让你设计一个订单号生成服务,该怎么做_.md
- 说一说多级缓存是如何应用的?.md
- 读取一千个文件,一个线程读取和开十个线程读取,哪种方式效率高?.md
- 调用第三方接口支付时,第三方接口显示支付成功,但是在调用方显示支付失败,问题可能出在哪里.md
- 进入电梯里断网后又恢复刚开始为什么网络慢?.md
- 项目中,如果日志打印成为瓶颈,该如何优化?.md
- 高并发的库存系统,在数据库扣减库存,怎么实现?.md
✅如何做平滑的数据迁移?
数据迁移指的是把一批数据从一个数据源迁移到另一个数据源中。要做好一个平滑的数据迁移,首先需要做一下整体的设计,主要包括数据评估、迁移目标等。
首先我们要知道数据为什么要做迁移,是因为做了分库分表、还是要替换数据库,还是技术架构发生变化,以及历史数据太多了要做归档?
当我们知道目的了之后,就可以进一步的看一下我们要迁移的数据量有多大。是几十万,几百万,千万级还是亿级。不同的数据量,迁移的方案肯定是不一样的。如果只是几十万,不需要搞那么复杂,直接写代码同步过来再做一下数据核对都能搞得定。
还有一个关键的东西需要考虑,那就是是否需要做平滑迁移,也就是说是不是迁移过程中需要对业务没有任何感知。如果可以停机迁移,那就随便搞了。
假设我们以上都确定了,按照比较复杂的情况来说吧,假设我们的技术架构发生了改变,原来的表要废弃还到新表,并且表结构还不一样,数据量大概有1个亿,并且每天的增量也有几十万,并且要求平滑迁移。
数据类型
对于数据迁移来说,一般包含两部分数据,一部分是存量数据,一部分是增量数据。
存量数据指的是已经在原库中的数据,增量数据指的是程序运行过程中新产生的数据。
也就是说我们定义一个时间点,从这个时间节点之后,新insert的数据叫做增量数据,但是新update和delete的数据不一定是存量也不一定是增量,要看他insert的时候是增量还是存量。
关键问题
我们在做数据迁移的时候,有很多问题需要重点考虑,只有这些问题都考虑到了,并且解决了,才能算得上是真的做到了平滑数据迁移。
数据完整性:确保迁移过程中所有数据都能准确无误地迁移到新系统,没有数据丢失。
数据实时性:对于实时性要求高的业务,需要保证旧系统和新系统数据的实时同步,直至完全切换到新系统。
数据校验:需要有一个数据核对和校验的机制,这样我们才能知道数据是否做好了迁移。
灰度控制:在迁移的过程中,我们需要逐步进行,一旦有问题尽量通过灰度的方式让对业务影响最小。
回滚机制:需要尽可能的支持回滚,一旦有问题,可以快速的做回滚。
可用工具
在做数据迁移的过程中,我们不一定全部都要自己通过写代码来实现迁移,尤其是存量数据,我们其实是可以通过一些工具来做迁移的。
DataX:是阿里云 DataWorks数据集成 的开源版本,在阿里巴巴集团内被广泛使用的离线数据同步工具/平台。DataX 实现了包括 MySQL、Oracle、OceanBase、SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、Hologres、DRDS, databend 等各种异构数据源之间高效的数据同步功能。

DataX在阿里巴巴集团内被广泛使用,承担了所有大数据的离线同步业务。
canal:要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费
早期阿里巴巴因为杭州和美国双机房部署,存在跨机房同步的业务需求,实现方式主要是基于业务 trigger 获取增量变更。从 2010 年开始,业务逐步尝试数据库日志解析获取增量变更进行同步,由此衍生出了大量的数据库增量订阅和消费业务。
Kettle:是一款开源的ETL(Extract, Transform, Load)工具,主要用于数据的抽取、转换和加载。通过Kettle,我们可以轻松地进行数据迁移,实现不同数据库之间的数据传输和整合。它允许你管理来自不同数据库的数据,通过提供一个图形化的用户环境来进行操作。
Flink CDC(Change Data Capture,即数据变更抓取)是一个开源的数据库变更日志捕获和处理框架,它可以实时地从各种数据库(如MySQL、PostgreSQL、Oracle、MongoDB等)中捕获数据变更并将其转换为流式数据。Flink CDC 可以帮助实时应用程序实时地处理和分析这些流数据,从而实现数据同步、数据管道、实时分析和实时应用等功能。
迁移流程
基于前面的讨论,如果我们想要实现迁移过程中的数据的完整性、实时性,预计对用户无感,通常是通过以下步骤进行迁移:

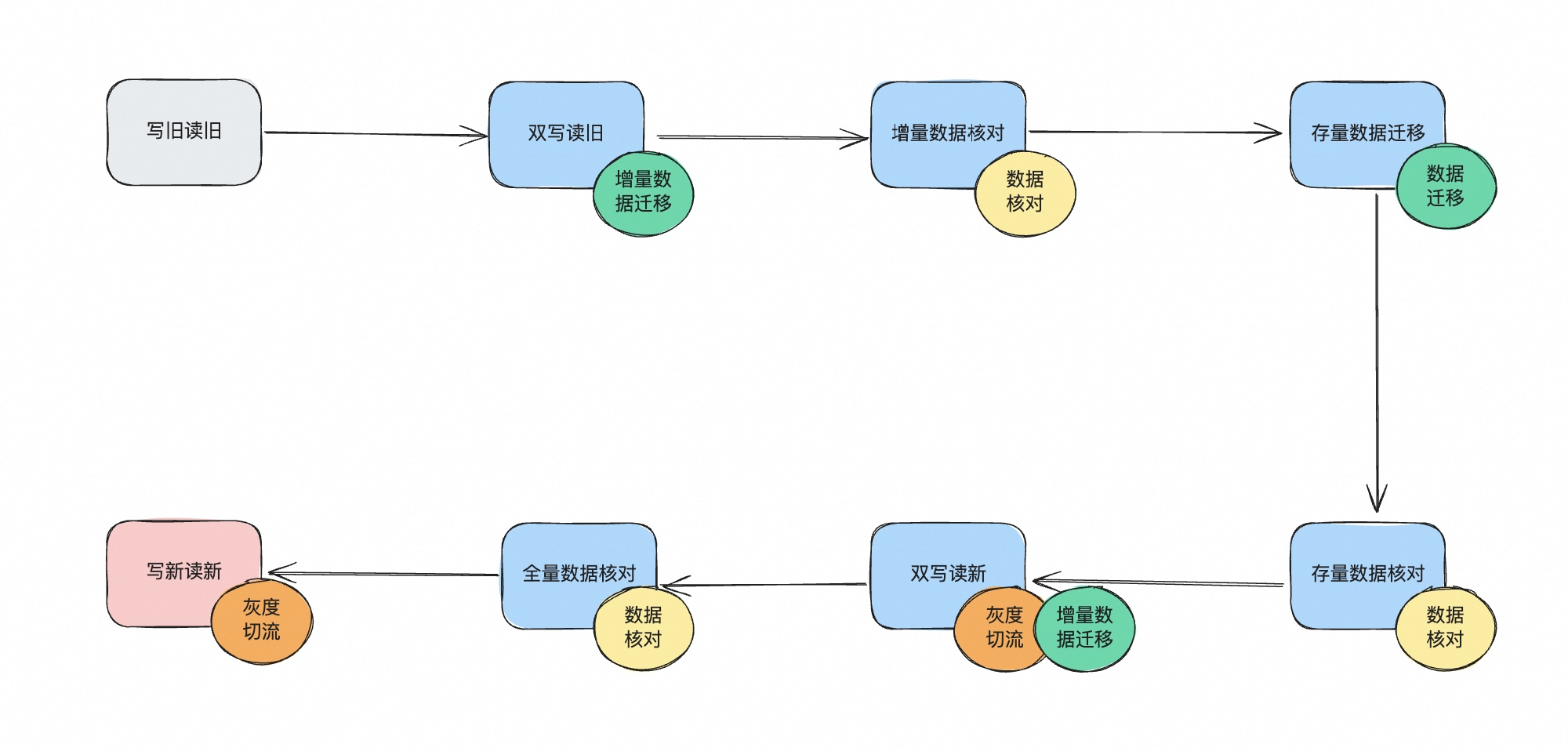
以上就是一个数据迁移的完整流程,从最开始的读写都从旧表进行,最终变成读写都从新表进行。
双写
数据双写是指同时进行新库和老库的写入,让新老库中同时都有最近的数据,这么做的主要原因一方面是让新数据不丢,另外也是随时可以做回滚。
双写的方案有很多,主要有以下这么几种:
- 借助工具增量双写,在增量双写过程中,我们可以用canal、flink cdc等这种增量数据更新的工具来进行双写,他们的原理就是在原库写入数据后,基于产生的binlog,自动把数据再写入新库。这个方案的好处是无需编码,支持各种异构的数据库,也支持表结构的各种不一致的转换。缺点就是有可能存在失败或者延迟的风险,一旦过程中出问题了,中间的数据可能会丢失。
- 通过代码实现双写,我们可以自己编码,在代码中实现双写,即写完旧库之后再写入新库。如果是同一个数据库的不同表的话,这里还可以借助事务保证数据的完整性。但是一般都是跨表或者跨库,所以这里需要考虑好重试的机制。优点就是代码实现的可靠性更强一些,逻辑可以自己定制,缺点就是需要写代码,比较复杂。
- 通过代码实现异步双写,这里同样是编码,但是我们不是直联数据库做写入,而是在写入新库的时候,通过MQ来做异步写入。
通过上面的流程图,其实可以发现,双写是几乎伴随着整个迁移的完整生命周期的,但是实际上,在第一次双写读旧(增量数据迁移) 和双写读新(增量数据迁移)的两个节点上,双写是不一样的,因为第一个阶段我们要保证旧库成功,新库可以失败(因为读发生在旧库上,要保证写入成功,否则会读不到数据)。但是第二个阶段,我们则需要保证新库必须成功,旧库可以失败。(因为读发生在新库上,要保证写入成功,否则会读不到数据)
所以,这就涉及到一个切换的问题,如果通过工具的话,就需要配置两个同步任务,最开始是旧表到新表,后面要改成新表到旧表。而这里如果用代码的话就好控制一点,我们可以提前把两个分支逻辑都写好,然后只需要在运行过程中通过配置做一下切换就好了,过程中有问题也可以随时切回来。
所以,建议在做增量同步的时候,采用写代码的方案,一般来说是直接在DAO层做代理去改代码。至于直接调数据库做双写,还是中间加一层MQ做双写,其实都可以。就看数据量了,如果比较大的话,可以用MQ做一下削峰填谷。
增量数据核对
在数据迁移过程中,做数据核对是至关重要的。尤其是增量数据,因为增量数据需要双写,双写是有可能失败的,所以需要有一定的机制可以发现这些双写失败的数据。
在做数据核对方面,有很多方式,https://www.yuque.com/hollis666/xkm7k3/vh0msbr3qrqzfrfm 这里讲过了,就不再赘述。
但是这里给大家建议一个方案,那就是做旁路验证。
当我们在做读操作的时候,不管是双写一阶段的读旧库,还是双写二阶段的读新库。我们都可以同时做一下旁路验证。
比如一阶段在做旧库的读的时候,我们可以通过旁路(可以起一个异步线程,或者通过MQ等)进行一次新库的读取,然后把拿到的结果和旧库的读取作比对,当发现不一致的时候,报警报出来,进行人工核对。
增量数据的更新
在数据迁移过程中,业务数据是会发生不断地变化的,前面的双写我们提了,只把新发生的insert当做增量。那这个过程中,如果发生了update,怎么办呢?
这里需要我们做一个逻辑,那就是在update/delete的时候,判断一下这个数据是增量的还是存量的,其实就是判断新表中是否有这个数据,如果有,就需要做双写更新,如果没有,就说明这是个存量数据,只更新旧表就行了。不用担心他们会丢,因为后续我们会做存量同步,这部分更新也会带过来的。
publiv viod update(){
if(增量数据){
同时更新旧表和新表();
}else{
更新旧表();
}
}
存量数据迁移
做好了增量数据迁移和核对之后,我们就可以把存量的数据也迁移过来了。
存量数据的迁移也有很多方案,比如自己写代码去扫表迁移,也可以通过工具做存量的数据同步。对于存量的数据迁移,需要考虑几个问题:
1、不能丢数据:迁移过程中,数据的完整性需要保证,不能中间丢了数据
2、断点能续传:迁移过程中,如果失败了,需要能够在失败处做断点续传,确保不重复不丢失。
3、不要覆盖增量数据:存量数据在迁移的过程中,新表中是有增量数据的,所以,需要确保存量数据的迁移,不会覆盖到这部分已经存在的增量数据。
4、迁移性能要好:存量数据一般都是量很大,所以迁移过程中的性能也是至关重要的。
为了保证数据不丢和能实现断点续传,我们可以在旧表中增加一个字段,来标识出这条记录是否已经被迁移过,这样我们就可以在一条记录迁移成功后,把他的这个标识改了,这样如果中间失败了,我们就知道哪些数据迁移过,哪些数据没迁移过,就只迁移这些没迁移的就行了。
有了这个标识之后,我们就可以做分批的迁移了,因为我们可以通过标记清晰的知道还有多少数据没迁移,可以方便的做分批处理和扫描。
为了不在存量数据迁移的过程中把增量数据覆盖了,这里就需要在insert之前做一个检查,判断下这个数据新表中是否已经存在了,已经存在的话,要么就是增量数据双写写进来的,要么就是上一次同步的时候失败了导致旧表的标记没来及更新,不管怎么样,直接认为这条记录已经迁移成功了就行。
因为我们做了双写,所以只要这条记录在新表中有(说明它是增量插入的,并且更新也同时进行了),就可以不用迁移了。否则就一定要迁移的(说明他是存量插入的,更新也只在旧表就行了)。
至于性能的问题,我们就需要通过各种手段来解决了,如果是用工具的话,很多工具是可以做一些参数配置的。如果是自己写代码,那么就可以用一些分布式任务+多线程,这个不展开讨论了,我们的八股文中有很多相关内容 。
存量数据核对
做完了存量的数据迁移之后,下一部就是要做灰度切流了,要把读请求从老表切流到新表了,在这之前就需要确保是否可以切流。
这里就是需要做数据核对了,把新表和旧表的数据做逐条核对,确保他们的数据是一模一样的。核对的可以看本八股文中核对的相关文章,可以借助很多工具来做。
切流读新
在确保数据都完成迁移之后,我们可以做切流了,但是我们一般是先把读请求切流到新的表上,跑一段时间,确保存量和增量数据都没问题,在切流写请求。
在切流的时候,需要有灰度的机制,可以基于用户ID的尾号,或者其他的业务字段来做切流,从10%,到20%,再到30%,50%,最后逐步放量到100%。
这一步在切流之后,我们的旁路的策略也需要跟着调整。因为切流后读新表了,那么旁路就需要切换到读旧表。
切流写新
这是最后一步了,这一步也是唯一的一步不能回滚的步骤了。
因为这一步我们就要把双写去掉,完全变成单写了,这一步之后,旧表的数据就不会再做更新了。所以,在这一步之前,要做好足够的验证和核对,确保数据无误之后,在做谨慎操作。建议先切流1%,或者0.1%这样的比例切流。
开关&监控
在这个过程中,我们可以看到,很多步骤都需要做各种调整,那么我们就需要在代码中提前放好开关,然后在上线之后,只需要通过推开关就可以做控制流程的切换了。
可以把这些开关配置到配置中心上,然后可以做到动态切换。
if(flag){
//
}else{
//
}
这里的flag就是个开关,他的值你可以通过配置中心进行动态的调整。
然后,除了核对以外,监控也至关重要,需要做好足够的监控来帮助我们提前的去发现问题。而且监控和核对是要覆盖了整个迁移流程的,一定不能裸奔!