- 首页
- 上一级
- 40亿个QQ号,限制1G内存,如何去重?.md
- 4C8G_16台和8C16G_8台,不考虑成本的情况怎么选?.md
- 4C8G的机器,各项系统指标,什么范围算是正常?.md
- InnoDB为什么不用跳表,Redis为什么不用B+树?.md
- Kafka,单分区单消费者实例,如何提高吞吐量.md
- MySQL千万级大表如何做数据清理?.md
- MySQL热点数据更新会带来哪些问题?.md
- MySQL里有2000W数据,Redis中只存20W的数据,如何保证Redis中的数据都是热点数据_.md
- Redis如果挂了,你怎么办?.md
- Redis的zset实现排行榜,实现分数相同按照时间顺序排序,怎么做?.md
- Redis的内存如果用满了,会挂吗?.md
- SpringEvent和MQ有什么区别?各自适用场景是什么?.md
- a,b的联合索引,selectbwherea=xx,无法走索引覆盖什么原因?.md
- 一个接口3000QPS,接口RT为200MS,预估需要几台机器?.md
- 一个支付单,多个渠道同时支付成功了怎么办?.md
- 一个表有用户和时间两个列,现有3个需求:根据用户查;根据日期查;根据日期和用户查;问怎么建立索引?.md
- 一个订单,在11_00超时关闭,但在11_00也支付成功了,怎么办?.md
- 一次RPC请求,客户端显示超时,但是服务端不超时,可能是什么原因?.md
- 不使用synchronized和Lock如何设计一个线程安全的单例?.md
- 不用redis分布式锁,如何防止用户重复点击?.md
- 不用大于号小于号怎么判断两个正整数大小?.md
- 为什么MySQL用B+树,MongoDB用B树?.md
- 为什么一定要做限流?不应该服务好客户吗?不应该是加机器吗?.md
- 为什么不建议使用MQ实现订单到期关闭?.md
- 为什么不用分布式锁来实现秒杀?.md
- 为什么不直接用原生的BlockinQueue做消息队列.md
- 为什么很多公司数据库不允许物理删除(delete)数据.md
- 为啥不要在事务中做外部调用?.md
- 从B+树的角度分析为什么单表2000万要考虑分表??.md
- 代码中使用长事务,会带来哪些问题?.md
- 你是如何进行SQL调优的?.md
- 你认为分布式架构一定比单体架构要好吗?.md
- 使用分布式锁时,分布式锁加在事务外面还是里面,有什么区别?.md
- 分布式系统,用户登录信息保存在服务器A上,服务器B如何获取到共享Session.md
- 分库分表时,每个城市的人口不一样,有的密集,有的稀疏,如何实现均匀分布?.md
- 加分布式锁之后影响并发了怎么办?.md
- 和其他公司做数据交互时,有什么需要注意的?.md
- 和外部机构交互如何防止被外部服务不可用而拖垮.md
- 在100M内存下存储一亿个整数,其范围在1到2亿,如何快速判断给定到一个整数值是否存在?.md
- 外卖系统,一天一千万条数据,用户需要查到近30天的数据,商家也要查询到30天的数据,怎么设计表?.md
- 大型电商的订单系统,如何设计分库分表方案?.md
- 大量的手机号码被标记成骚扰电话,如何存储这些号码_.md
- 如何做SQL调优:用了主键索引反而查询很慢?.md
- 如何做平滑的数据迁移_.md
- 如何实现_查找附近的人_功能?.md
- 如何实现一个抢红包功能?.md
- 如何实现敏感词过滤?.md
- 如何实现百万级排行榜功能?.md
- 如何实现百万级数据从Excel导入到数据库?.md
- 如何实现缓存的预热?.md
- 如何用Redis实现朋友圈点赞功能?.md
- 如何解决消息重复消费、重复下单等问题?.md
- 如何设计一个购物车功能?.md
- 如何预估一个系统的QPS?.md
- 如果你的业务量突然提升100倍QPS你会怎么做?.md
- 如果单表数据量大,只能考虑分库分表吗?.md
- 如果要存IP地址,用什么数据类型比较好?.md
- 如果让你实现一个RPC框架,会考虑用哪些技术解决哪些问题?.md
- 如果让你实现消息队列,会考虑哪些问题?.md
- 如果需要跨库join,该如何实现?.md
- 实现一个登录拉黑功能,实现拉黑用户和把已经登陆用户踢下线。.md
- 库存扣减如何避免超卖和少卖?.md
- 应用占用内存持续增长,但是堆内存、元空间都没变化,可能是什么原因?.md
- 应用启动后前几分钟,Load、RT、CPU等飙高,如何定位,可能的原因是什么?.md
- 怎么做数据对账?.md
- 把商品加入购物车时断网了,该怎么在重新联网时同步?.md
- 数据库乐观锁和悲观锁以及redis分布式锁的区别和使用场景?.md
- 数据库逻辑删除后,怎么做唯一性约束?.md
- 每天100w次登录请求,4C8G机器如何做JVM调优?.md
- 消息队列使用拉模式好还是推模式好?为什么?.md
- 用了一锁二查三更新,为啥还出现了重复数据?.md
- 电商下单场景,如何设计一个数据一致性方案?.md
- 索引失效的问题是如何排查的,有那些种情况?.md
- 线上接口如果响应很慢如何去排查定位问题呢?.md
- 给第三方提供接口调用,需要注意些什么?.md
- 订单到期关闭如何实现.md
- 让你设计一个秒杀系统,你会考虑哪些问题?.md
- 让你设计一个订单号生成服务,该怎么做_.md
- 说一说多级缓存是如何应用的?.md
- 读取一千个文件,一个线程读取和开十个线程读取,哪种方式效率高?.md
- 调用第三方接口支付时,第三方接口显示支付成功,但是在调用方显示支付失败,问题可能出在哪里.md
- 进入电梯里断网后又恢复刚开始为什么网络慢?.md
- 项目中,如果日志打印成为瓶颈,该如何优化?.md
- 高并发的库存系统,在数据库扣减库存,怎么实现?.md
✅如何实现敏感词过滤?
典型回答
敏感词过滤是非常常见的一种手段,避免出现一些违规词汇。在实现上,有很多种方案。
字符串匹配
字符串匹配是最简单、直观的方法,直接在文本中查找是否存在敏感词列表中的词汇。如在Java中使用contains方法或者正则表达式都可以判断。
但是他只适合小规模文本或敏感词较少的场合下使用,比如我们在避免SQL注入的时候,需要对用户输入的内容进行一些特殊字符的过滤,就可以用这种方式,又或者是我们在做数据脱敏的时候,也可以用这种方式实现。
他的优点就是,实现简单,易于理解。但是缺点也很明显,就是效率比较低,特别是在处理大量文本或敏感词库较大时。还有就是无法处理变体词汇,如错别字、同音字等。
因为字符串匹配的基本原理是遍历待检测的文本,对于每一个可能的起始位置,检查是否有敏感词与之匹配。如以下是String中contains方法的主要实现:
public boolean contains(CharSequence s) {
return indexOf(s.toString()) > -1;
}
public int indexOf(int ch, int fromIndex) {
final int max = value.length;
if (fromIndex < 0) {
fromIndex = 0;
} else if (fromIndex >= max) {
// Note: fromIndex might be near -1>>>1.
return -1;
}
if (ch < Character.MIN_SUPPLEMENTARY_CODE_POINT) {
// handle most cases here (ch is a BMP code point or a
// negative value (invalid code point))
final char[] value = this.value;
for (int i = fromIndex; i < max; i++) {
if (value[i] == ch) {
return i;
}
}
return -1;
} else {
return indexOfSupplementary(ch, fromIndex);
}
}
可以看到它是通过一个for循环从头开始进行便利的。
对于长度为N的文本和M个敏感词,如果简单地使用遍历的方式进行字符串匹配,其时间复杂度接近于O(N×M),在敏感词数量或文本长度大时,这将导致显著的性能瓶颈。
前缀树
前缀树,也被称为Trie树,是一种用于快速检索字符串数据集中的键的树形数据结构。
这种数据结构特别适合解决与一组字符串有关的问题,如自动补全、拼写检查、词频统计、敏感词过滤等。前缀树的核心优势在于,它能够通过共享前缀来最大化地减少查询和存储空间,特别是当处理大量具有共同前缀的字符串时。
前缀树比较适合敏感词有共同前缀的场景,如具有相同根词的不同变形。并且他比字符串更加适合大量敏感词和长文本的处理。
前缀树用于敏感词过滤的实现主要有以下步骤:
1、构建前缀树:
将所有敏感词逐个添加到前缀树中。
具体操作是:对于每个敏感词,从根节点开始,按照敏感词的字符顺序,逐个检查当前字符是否已经作为子节点存在。如果不存在,就创建一个新的节点,将当前字符存入节点,并将节点加入当前遍历节点的子节点集合中;如果存在,就继续沿着该子节点向下遍历。直到敏感词的所有字符都被添加到树中,标记最后一个字符对应的节点为一个敏感词的结束。
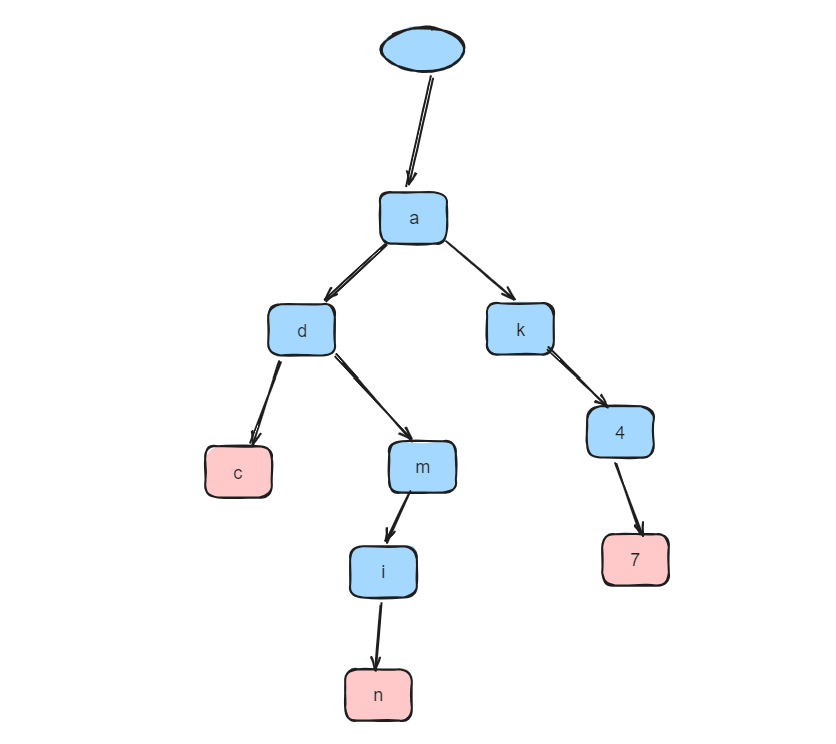
假设我们有敏感词列表["adc", "ak47", "admin"],我们首先根据这个列表构建前缀树:
- 根节点不包含字符,它的子节点为a。
- a节点的子节点为d、k。d节点的子节点为c和m,k节点的子节点为4
- 如此构建下去的前缀树如下: +
2、敏感词过滤:
当需要检测一段文本是否包含敏感词时,可以将文本的每个字符作为起点,尝试在前缀树中进行匹配。
具体操作是:从文本的当前字符开始,尝试与前缀树的根节点的子节点进行匹配;如果匹配成功,则继续匹配下一个字符和当前节点的子节点;如果匹配不成功,则从文本的下一个字符重新开始匹配;如果匹配过程中到达了标记为敏感词结束的节点,则说明文本中包含敏感词。根据需要,可以直接标记敏感词位置,或者替换敏感词。
如果我们需要过滤一段文本:“this admin has an ak47”,我们从第一个字符t开始,在前缀树中进行匹配。直到我们到达a时,开始匹配到admin,这时我们发现admin是一个敏感词,可以进行相应的标记或替换操作。同样的过程适用于ak47。
前缀树的优点是,插入和查询效率高,特别是在敏感词有共同前缀的情况下(如ab、abc、abcd)。而且他的空间效率较高,因为是共享公共前缀的。
但是他也有缺点,一方面是构建树的初期成本较高。另外对于没有共同前缀的敏感词,效率提升不明显。
所以,前缀树适合做高效的字典查找、根据前缀自动补全、利用前缀匹配进行快速路由等场景。
DFA算法
DFA是Deterministic Finite Automaton的缩写,翻译过来叫确定有限自动机,DFA算法是一种高效的文本匹配算法,特别适合于敏感词过滤。
DFA由一组状态组成,以及在这些状态之间的转换,这些转换由输入字符串驱动。每个状态都知道下一个字符的到来应该转移到哪个状态。如果输入字符串结束时,DFA处于接受状态,则输入字符串被认为是匹配的。
前缀树用于敏感词过滤的实现主要有以下步骤:
1、构建DFA:
首先,为每个敏感词构建DFA。这个过程从一个初始状态开始,对于敏感词中的每个字符,如果当前状态下没有对应该字符的转换,则创建一个新的状态,并添加一条从当前状态到新状态的转换,这条转换由该字符触发。如果已经有了对应该字符的转换,则沿着这条转换到达下一个状态。重复这个过程直到敏感词的每个字符都被处理。最后一个字符对应的状态被标记为接受状态,意味着到达这个状态表示找到了一个敏感词。
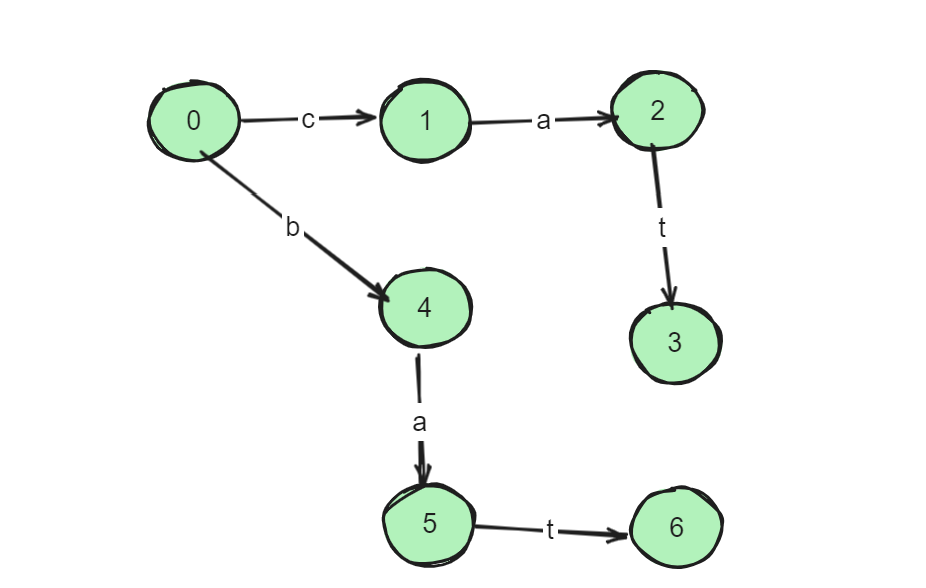
假设我们的敏感词列表包含["cat", "bat"]。我们首先根据这个列表构建DFA:
- 初始状态0,对于输入c转到状态1,对于输入b转到状态4。
- 状态1,对于输入a转到状态2。
- 状态2,对于输入t转到状态3,状态3是接受状态,意味着找到了敏感词cat。
- 同理,状态4对于输入a转到状态5,状态5对于输入t转到状态6,状态6是接受状态,意味着找到了敏感词bat。
2、过滤文本:
当需要检测一段文本时,从DFA的初始状态和文本的第一个字符开始。对于文本中的每个字符,根据当前状态和字符确定下一个状态。如果存在对应字符的转换,则跟随这条转换到达下一个状态;如果不存在,则返回到初始状态。如果在某个点达到了接受状态,意味着匹配到了一个敏感词。然后可以选择标记或替换该敏感词,并继续处理文本的剩余部分。
现在,如果我们需要过滤一段文本:“The cat sat on the mat.”,我们从初始状态0开始,遇到c转到状态1,接着a转到状态2,然后t转到状态3,此时达到接受状态,意味着我们发现了敏感词cat。根据需要,可以对这个敏感词进行标记或替换,然后继续处理文本的剩余部分。
DFA适合复杂模式匹配,如正则表达式匹配。以及网络内容过滤和安全审计,用于检测和过滤特定模式的文本。
扩展知识
开源框架
给大家推荐一个基于 DFA 算法实现的高性能 java 敏感词过滤工具框架——sensitive-word
https://github.com/houbb/sensitive-word