✅Nacos 2.x为什么新增了RPC的通信方式?
典型回答
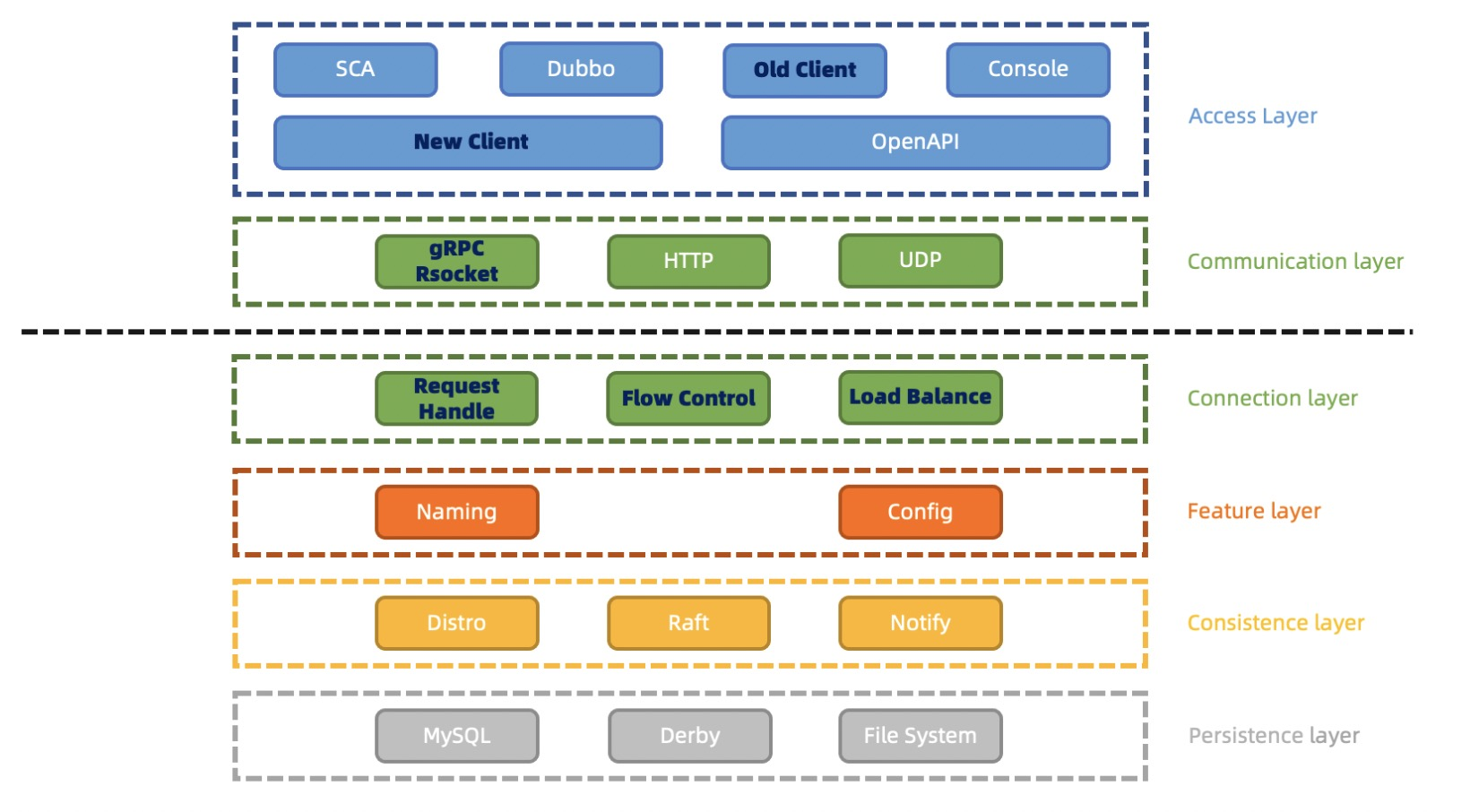
Nacos 2.X 在 1.X 的架构基础上,通信层通过 gRPC 和 Rsocket 实现了长连接 RPC 调用和推送能力。主要是为了改善Nacos在大规模集群环境下的性能和稳定性。**
同时新增一个链接层,用来将不同类型的 Request 请求,将来自不同客户端的不同类型请求,转化为相同语意的功能数据结构,复用业务处理逻辑。同时,将来的流量控制和负载均衡等功能也会在链接层处理。
在Nacos的早期版本中,节点之间的通信采用了HTTP协议。在高并发、大规模集群环境下,由于HTTP的连接管理和请求响应的开销,会导致一些性能和稳定性方面的问题。
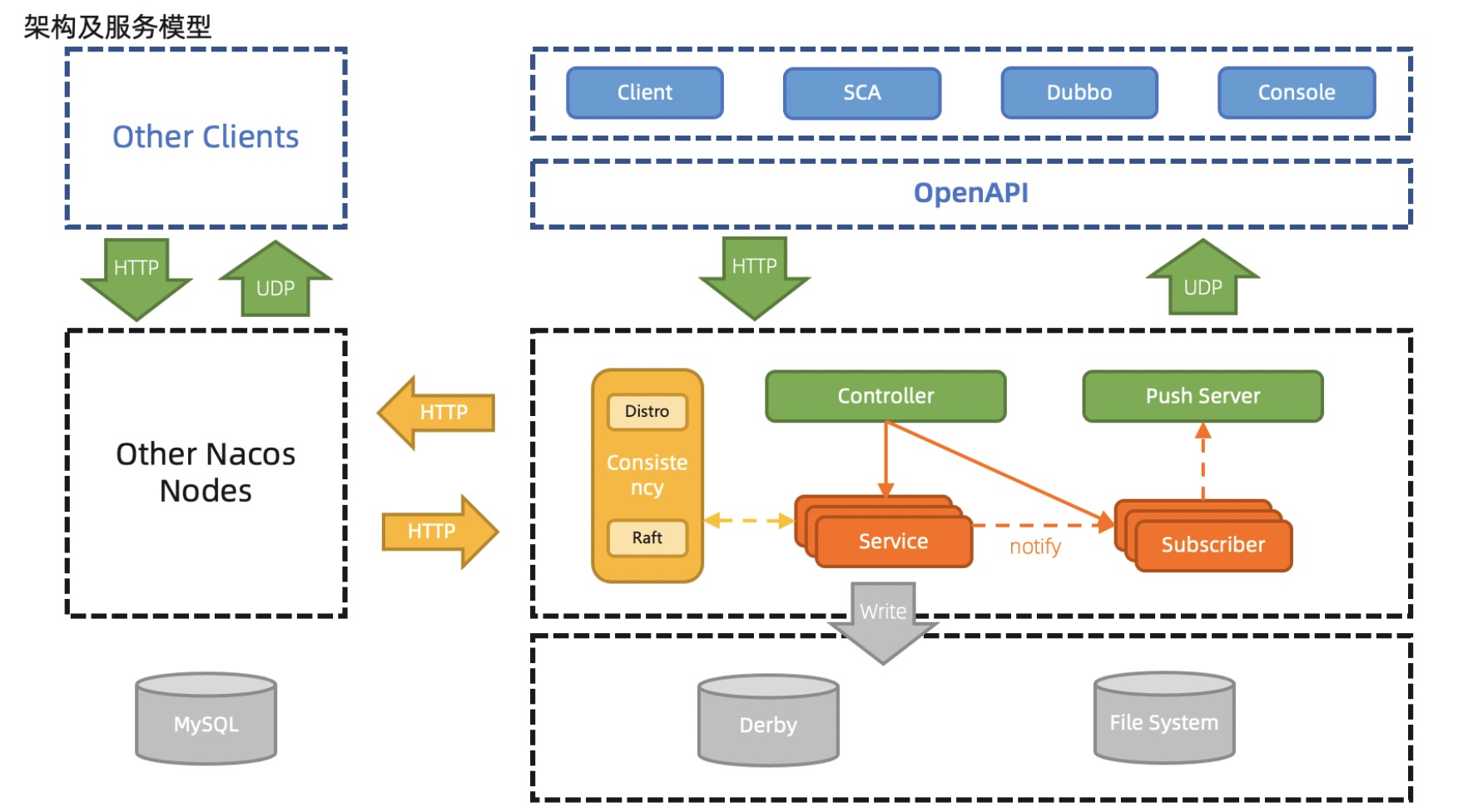
HTTP 短连接模型,每次客户端请求都会创建和销毁 TCP 链接,TCP 协议销毁的链接状态是 WAITTIME,完全释放还需要一定时间,当 TPS 和 QPS 较高时,服务端和客户端可能有大量的 WAITTIME 状态链接,从而会导致 connect time out 错误或者 Cannot assign requested address 的问题。
配置模块使用 HTTP 短连接阻塞模型来模拟长连接通信,但是由于并非真实的长连接模型,因此每 30 秒需要进行一次请求和数据的上下文切换,每一次切换都有引起造成一次内存浪费,从而导致服务端频繁 GC。
在大规模集群环境下,维护大量的HTTP连接会给负载均衡、路由等方面的管理带来一定的复杂性。并且HTTP协议对请求和响应的内容通常需要进行压缩和序列化处理,这也会带来一定的开销。
同时,1.0的版本中还存在以下几个问题:
通过心跳续约,当服务规模上升时,特别是类似 Dubbo 的接口级服务较多时,心跳及配置元数据的轮询数量众多,导致集群 TPS 很高,系统资源高度空耗。
心跳续约需要达到超时时间才会移除并通知订阅者,默认为 15s,时延较长,时效性差。若改短超时时间,当网络抖动时,会频繁触发变更推送,对客户端服务端都有更大损耗。
为了解决这些问题,Nacos 2.x引入了gRPC的通信方式
Nacos2架构下的服务发现,客户端通过gRPC,发起注册服务或订阅服务的请求。服务端使用Client对象来记录该客户端使用gRPC连接发布了哪些服务,又订阅了哪些服务,并将该Client进行服务间同步。由于实际的使用习惯是服务到客户端的映射,即服务下有哪些客户端实例。
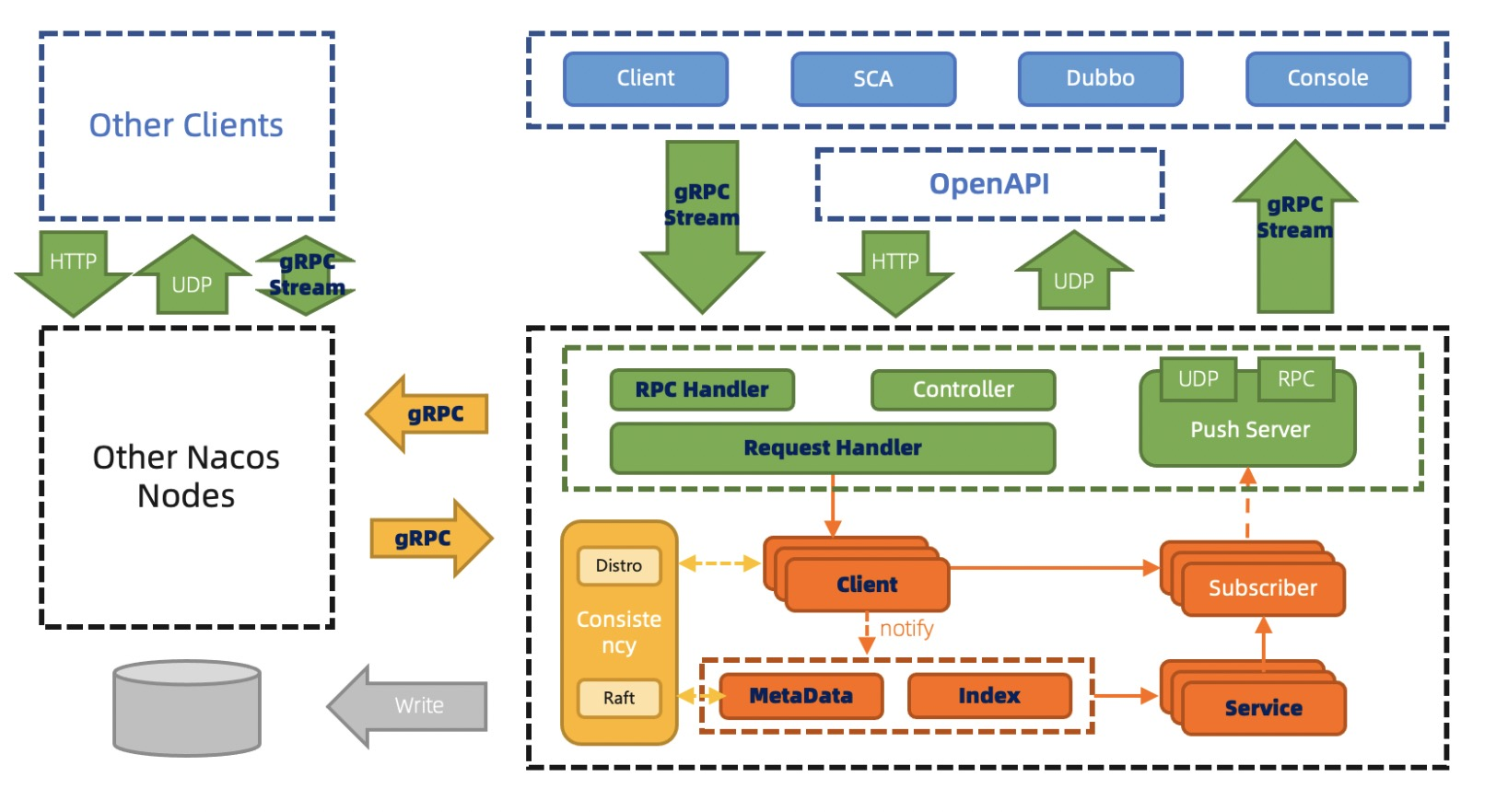
配置管理之前用Http1.1的Keep Alive模式30s发一个心跳模拟长链接,协议难以理解,内存消耗大,推送性能弱,因此2.0通过gRPC彻底解决这些问题,内存消耗大量降低。
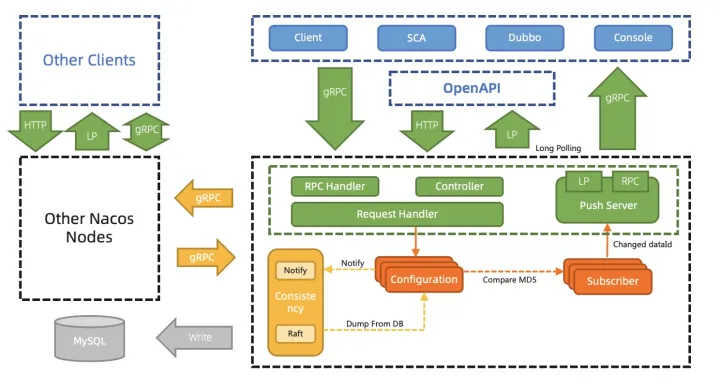
- 客户端不再需要定时发送实例心跳,只需要有一个维持连接可用 keepalive 消息即可。重复 TPS 可以大幅降低。
- TCP 连接断开可以被快速感知到,提升反应速度。
- 长连接避免频繁连接开销,可以大幅缓解 TIME_ WAIT 问题。
- 真实的长连接,解决配置模块 GC 问题。
- 更细粒度的同步内容,减少服务节点间的通信压力。
当然,缺点也是存在的。那就是RPC 协议的观测性不如 HTTP。即使 gRPC 基于 HTTP2.0 Stream 实现,仍然不如直接使用 HTTP 协议来的直观。
原文: https://www.yuque.com/hollis666/xkm7k3/cp3zuisb11nsd2h8
