✅Zookeeper是CP的还是AP的?
典型回答
ZooKeeper作为分布式协调服务,它的职责是保证数据(注:配置数据,状态数据)在其管辖下的所有服务之间保持同步、一致。所以,我们可以认为Zookeeper是一个CP的分布式系统。所以他会牺牲可用性,也就是在极端环境下,ZooKeeper可能会丢弃一些请求,消费者程序需要重新请求才能获得结果。
这个 CP体现在以下几个情况下:
1、如果集群中的存活节点数低于总结点数的一半,那么整个集群将无法接受新的写请求。
2、在 ZK 的 master 选举过程中,在新的Master被选举出来之前,整个集群也无法接受新的写请求。
而且, 作为ZooKeeper的核心实现算法 Zab,就是解决了分布式系统下数据如何在多个服务之间保持同步问题的。
如果 ZooKeeper下所有节点都断开了,或者集群中出现了网络分割的故障(注:由于交换机故障导致交换机底下的子网间不能互访);那么ZooKeeper 会将它们都从自己管理范围中剔除出去,外界就不能访问到这些节点了,即便这些节点本身是“健康”的,可以正常提供服务的;所以导致到达这些节点的服务请求被丢失了。
但是,请一定要注意,这里面的一致性,他确实是强一致性,但是,Zookeeper保证的是强一致模型中的顺序一致性而不是线性一致性。 (这个很少有人提)
✅什么是分布式系统的一致性?
这一点在ZK的官网(https://zookeeper.apache.org/doc/r3.4.13/zookeeperProgrammers.html )上明确的说过:
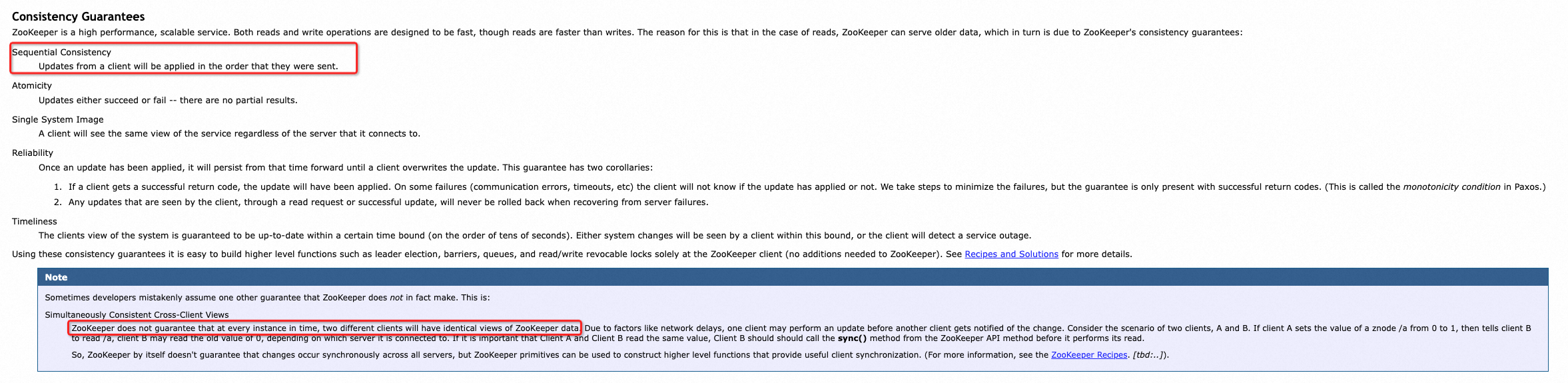
这里明确的提了,Zookeeper是保证的顺序一致性,也就是说,ZooKeeper不保证在每个时间点,两个不同的客户端将具有相同的ZooKeeper数据视图。但是他能保证我们在每个节点上读取到的一定是他最后一次更新的内容。
具体的案例就是,当Zookeeper在进行数据同步的过程中,如果半数节点同步成功,它就提交当前事务,但此时集群内还有可能有节点没有同步到数据,如果此时读请求发送到没有同步到数据的节点,那么就会读到旧的数据。
但是Zookeeper是会保证这个节点最终也会按照顺序执行成功的。
扩展知识
如何保证真正的强一致性?
想要让Zookeeper真正的保证强一致性,或者说保证线性一致性也是有办法的,那就是通过sync命令。
当我们对一个Follower调用sync命令的时候,会使得他和Leader节点进行数据同步,并等待服务器同步完成之后再返回。这样下一次的read就能保证拿到的是最新数据了。
原文: https://www.yuque.com/hollis666/xkm7k3/lxznb86av97adwt6
