✅你知道哪些缓存失效算法?
缓存失效算法主要是进行缓存失效的,当缓存中的存储的对象过多时,需要通过一定的算法选择出需要被淘汰的对象,一个好的算法对缓存的命中率影响是巨大的。常见的缓存失效算法有FIFO、LRU、LFU,以及Caffeine中的Window TinyLFU算法。
FIFO
FIFO 算法是一种比较容易实现也最容易理解的算法。它的主要思想就是和队列是一样的,即先进先出(First In First Out)
一般认为一个数据是最先进入的,那么可以认为在将来它被访问的可能性很小。
因为FIFO刚好符合队列的特性,所以通常FIFO的算法都是使用队列来实现的:
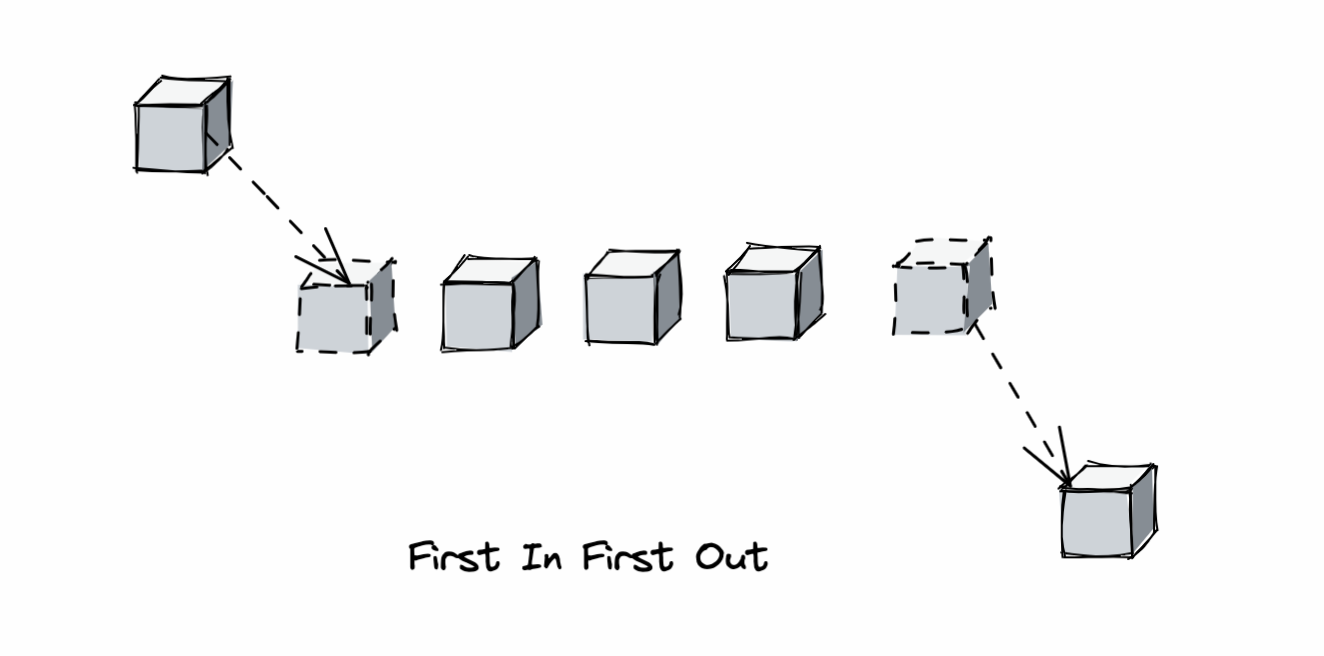
新数据插入到队列尾部,数据在队列中顺序移动;
淘汰队列头部的数据;
LRU&LFU
✅LRU 和 LFU 有啥区别?
W-TinyLFU
LFU 通常能带来最佳的缓存命中率,但 LFU 有两个缺点:
- 它需要给每个记录项维护频率信息,每次访问都需要更新,需要一个巨大的空间记录所有出现过的 key 和其对应的频次;
- 如果数据访问模式随时间有变,LFU 的频率信息无法随之变化,因此早先频繁访问的记录可能会占据缓存,而后期访问较多的记录则无法被命中;
- 如果一个刚加入缓存的元素,它的频率并不高,那么它可能会会直接被淘汰。
其中第一点过于致命导致我们通常不会使用 LFU。我们最常用的 LRU 实现简单,内存占用低,但其并不能反馈访问频率。LFU 通常需要较大的空间才能保证较好的缓存命中率。
W-TinyLFU是一种高效的缓存淘汰算法,它是TinyLFU算法的一种改进版本,主要用于处理大规模缓存系统中的淘汰问题。W-TinyLFU的核心思想是基于窗口的近似最少使用算法,即根据数据的访问模式动态地调整缓存中数据的淘汰策略。W-TinyLFU 综合了LRU和LFU的长处:高命中率、低内存占用。
W-TinyLFU由多个部分组合而成,包括窗口缓存、过滤器和主缓存。
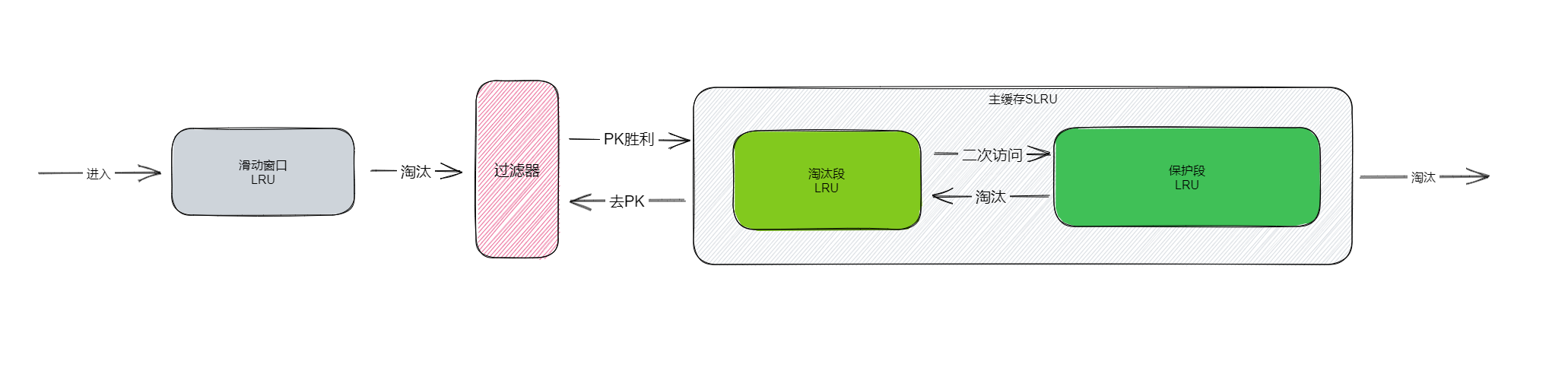
使用LRU来作为一个窗口缓存,主要是让元素能够有机会在窗口缓存中去积累它的频率,避免因为频率很低而直接被淘汰。
主缓存是使用SLRU,元素刚进入W-TinyLFU会在窗口缓存暂留一会,被挤出窗口缓存时,会在过滤器中和主缓存中最容易被淘汰的元素进行PK,如果频率大于主缓存中这个最容易被淘汰的元素,才能进入主缓存。
原文: https://www.yuque.com/hollis666/xkm7k3/gl3fivks74z4d10e
