✅什么是全链路压测?
典型回答
全链路压测诞生于阿里巴巴双11备战过程,如果说双11大促是阿里业务的“期末考试”,全链路压测就是大考前的“模拟考试”。全链路压测通过在生产环境对业务大流量场景进行高仿真模拟,获取最真实的线上实际承载能力、执行精准的容量规划,确保系统可用性。
因为对于像阿里这种大型互联网公司来说,尤其是电商业务,一个业务流程涉及到的上下游实在是太多了。任何一个节点都可能成为整个系统的瓶颈。
而在单链路压测时,往往只关注自己的系统,就会不可避免忽略掉一些资源竞争及外部干扰,最终得到一个过于乐观的结果。
并且在分布式场景中,我们和上下游之间的依赖关系错综复杂,只有在全链路压测中才能真正的暴露出真实环境中的各种问题。
全链路压测可以从网络到Nginx反向代理、到应用服务器、系统间依赖、数据库、缓存、磁盘等全方位的找出系统瓶颈。
但是全链路压测和单链路压测有个比较大的不同,那就是对于很多下游系统来说,他需要能识别出压测流量,一方面可以对这些流量做一些特殊处理,比如某个系统大促当天会被降级,那么他就可以直接把压测流量过滤掉,不参加压测。
还有就是,很多时候压测都不仅仅是读操作,还有很多写操作,那就会在很多系统中产生数据,那么就需要把这部分流量识别出来,把这部分数据做好隔离。
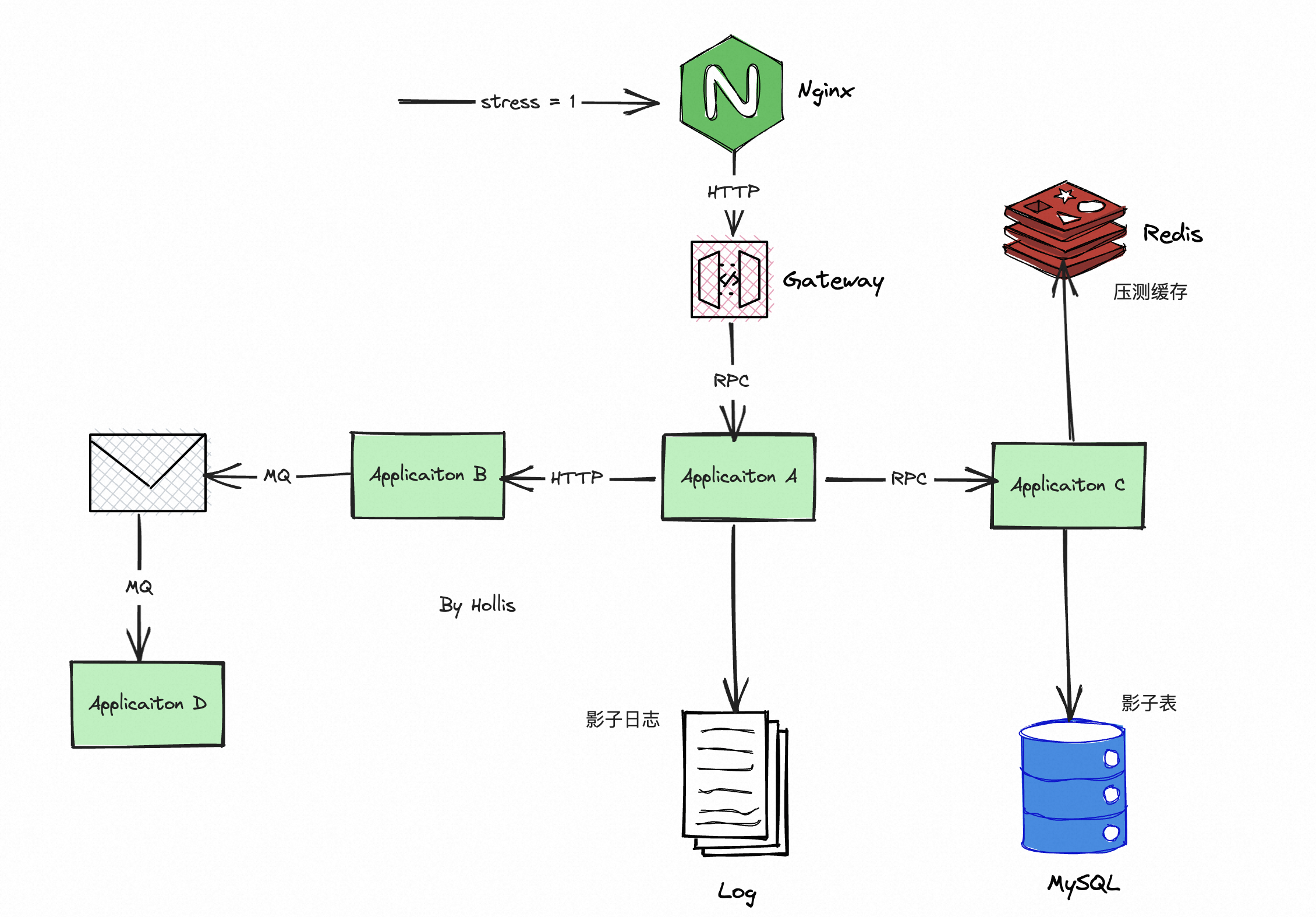
所以,全链路压测中比较重要的就是流量识别及数据隔离。
流量识别
在流量识别方面,一般都是通过流量染色实现的,其实就是对各种服务框架进行改造,比如DUBBO、REDIS、TDDL、MQ等所有的系统间交互以及存储等需要用到的组件中做改造。
比如定义一个特殊的字段,如fullchainstress_tag,把他在整个链路中都传递下去,然后这样各个系统就可以有效的识别出压测流量了。
这个也可以和分布式链路追踪结合着来做,理论上大家要该干的事儿是一样的。
数据隔离
数据隔离一般都是用影子表。比如我们有一张order表,那么在压测前就需要创建一张order__shadow表,作为他的影子表。
这样在数据库持久层,就需要识别出压测流量,然后把压测数据写入到影子表中。这样就可以避免对真实数据产生影响。
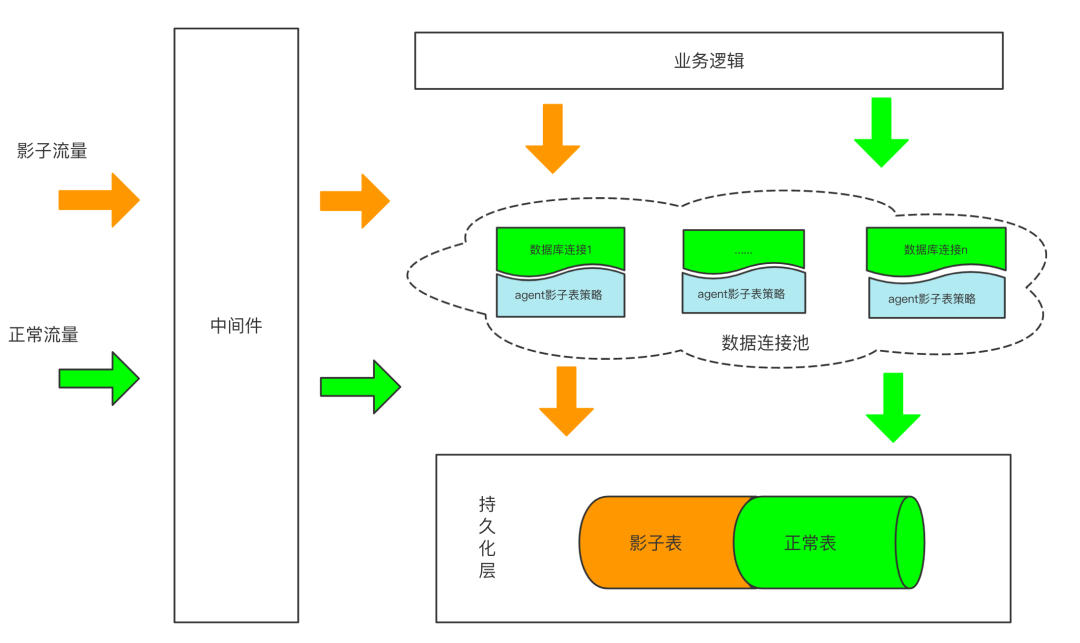
除了数据库,还有缓存,也一样,也需要识别压测流量,然后写入到对应的影子缓存中。还有日志,如果有需要,也可以做隔离。
工具
目前市面上可以用的全链路压测工具有Takin、Quake(美团)、Rhino(字节)、ForceBot
以下是一些行业内大厂的一些压测的分享(外链):
原文: https://www.yuque.com/hollis666/xkm7k3/igx3g283upzhgpm4
