
- 首页
- 上一级
- AQS为什么采用双向链表?.md
- AQS是如何实现线程的等待和唤醒的?.md
- AQS的同步队列和条件队列原理?.md
- CAS一定有自旋吗?.md
- CAS在操作系统层面是如何保证原子性的?.md
- CompletableFuture的底层是如何实现的?.md
- CountDownLatch、CyclicBarrier、Semaphore区别?.md
- ForkJoinPool和ThreadPoolExecutor区别是什么?.md
- JDK21中的虚拟线程是怎么回事?.md
- Java是如何判断一个线程是否存活的?.md
- Java线程出现异常,进程为啥不会退出?.md
- LongAdder和AtomicLong的区别?.md
- Thread.sleep(0)的作用是什么?.md
- ThreadLocal为什么会导致内存泄漏?如何解决的?.md
- ThreadLocal的应用场景有哪些?.md
- happens-before和as-if-serial有啥区别和联系?.md
- inta=1是原子性操作吗.md
- run_start、wait_sleep、notify_notifyAll区别_.md
- sychronized是非公平锁吗,那么是如何体现的?.md
- synchronized升级过程中有几次自旋?.md
- synchronized和reentrantLock区别?.md
- synchronized是如何保证原子性、可见性、有序性的?.md
- synchronized是怎么实现的?.md
- synchronized的锁优化是怎样的?.md
- synchronized的锁升级过程是怎样的?.md
- synchronized的锁能降级吗?.md
- synchronized锁的是什么?.md
- volatile是如何保证可见性和有序性的?.md
- volatile能保证原子性吗?为什么?.md
- 三个线程分别顺序打印0-100.md
- 为什么JDK15要废弃偏向锁?.md
- 为什么不建议通过Executors构建线程池.md
- 为什么不能在try-catch中捕获子线程的异常_.md
- 为什么虚拟线程不能用synchronized?.md
- 为什么虚拟线程不要和线程池一起用?.md
- 为什么虚拟线程尽量避免使用ThreadLocal.md
- 什么是AQS的独占模式和共享模式?.md
- 什么是CAS?存在什么问题?.md
- 什么是Java内存模型(JMM)?.md
- 什么是ThreadLocal,如何实现的?.md
- 什么是Unsafe?.md
- 什么是happens-before原则?.md
- 什么是可重入锁,怎么实现可重入锁?.md
- 什么是多线程中的上下文切换?.md
- 什么是守护线程,和普通线程有什么区别?.md
- 什么是并发,什么是并行?.md
- 什么是总线嗅探和总线风暴,和JMM有什么关系?.md
- 什么是死锁,如何解决?.md
- 什么是线程池,如何实现的?.md
- 公平锁和非公平锁的区别?.md
- 创建线程有几种方式?.md
- 到底啥是内存屏障?到底怎么加的?.md
- 如何保证多线程下i++结果正确?.md
- 如何实现主线程捕获子线程异常.md
- 如何对多线程进行编排.md
- 如何理解AQS?.md
- 如何让Java的线程池顺序执行任务?.md
- 并发编程中的原子性和数据库ACID的原子性一样吗?.md
- 有三个线程T1,T2,T3如何保证顺序执行?.md
- 有了CAS为啥还需要volatile?.md
- 有了InheritableThreadLocal为啥还需要TransmittableThreadLocal?.md
- 有了MESI为啥还需要JMM?.md
- 有了synchronized为什么还需要volatile_.md
- 有哪些实现线程安全的方案_.md
- 父子线程之间怎么共享_传递数据?.md
- 线程同步的方式有哪些?.md
- 线程数设定成多少更合适?.md
- 线程是如何被调度的?.md
- 线程有几种状态,状态之间的流转是怎样的?.md
- 线程池的拒绝策略有哪些?.md
- 能不能谈谈你对线程安全的理解?.md
✅AQS为什么采用双向链表?
典型回答
AbstractQueuedSynchronizer (抽象队列同步器,以下简称 AQS)出现在 JDK 1.5 中。他是很多同步器的基础框架,比如 ReentrantLock、CountDownLatch 和 Semaphore 等都是基于 AQS 实现的。
上面这篇介绍过,在AQS内部,维护了一个FIFO队列和一个volatile的int类型的state变量。在state=1的时候表示当前对象锁已经被占有了,state变量的值修改的动作通过CAS来完成。
这个FIFO队列用来实现多线程的排队工作,他本质上是一个双向链表,因为他定义了两个Node,一个prev,一个next,这就是典型的双向链表。
public abstract class AbstractQueuedSynchronizer
extends AbstractOwnableSynchronizer
implements java.io.Serializable {
/**
* Link to predecessor node that current node/thread relies on
* for checking waitStatus. Assigned during enqueuing, and nulled
* out (for sake of GC) only upon dequeuing. Also, upon
* cancellation of a predecessor, we short-circuit while
* finding a non-cancelled one, which will always exist
* because the head node is never cancelled: A node becomes
* head only as a result of successful acquire. A
* cancelled thread never succeeds in acquiring, and a thread only
* cancels itself, not any other node.
*/
volatile Node prev;
/**
* Link to the successor node that the current node/thread
* unparks upon release. Assigned during enqueuing, adjusted
* when bypassing cancelled predecessors, and nulled out (for
* sake of GC) when dequeued. The enq operation does not
* assign next field of a predecessor until after attachment,
* so seeing a null next field does not necessarily mean that
* node is at end of queue. However, if a next field appears
* to be null, we can scan prev's from the tail to
* double-check. The next field of cancelled nodes is set to
* point to the node itself instead of null, to make life
* easier for isOnSyncQueue.
*/
volatile Node next;
}
在AQS的源码中,有一个图画了一下这个队列,但是他画的是单链表,但是其实现上是双链表的。
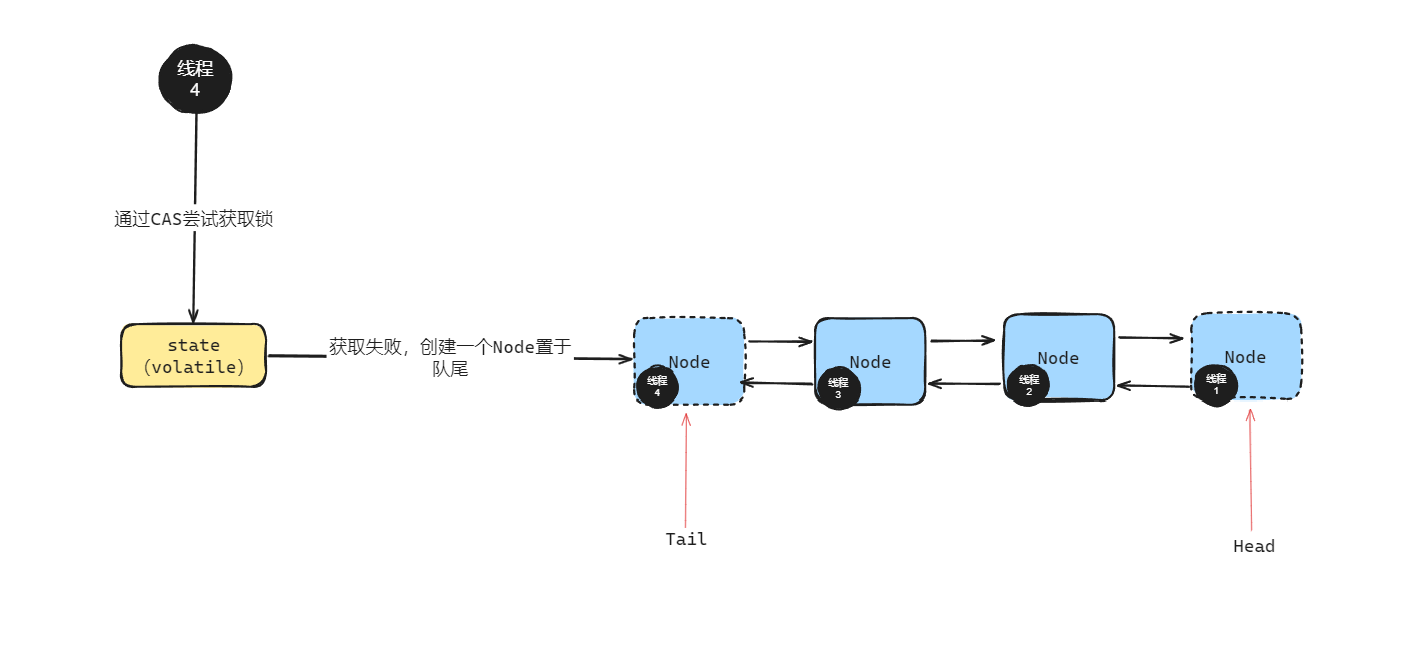
为什么这里要使用双向链表,而不是单向链表呢?好处是什么呢?
单链表和双向链表的区别
要搞清楚这个问题,想要理解下单链表和双向链表之间的区别。
- 单向链表的每个节点只包含一个链接,该链接指向列表中的下一个节点。列表的遍历只能是单向的,从头节点开始一直到尾节点。
- 双向链表中的每个节点都有两个链接:一个指向前一个节点,另一个指向后一个节点。这种结构允许双向遍历:从头到尾或从尾到头。
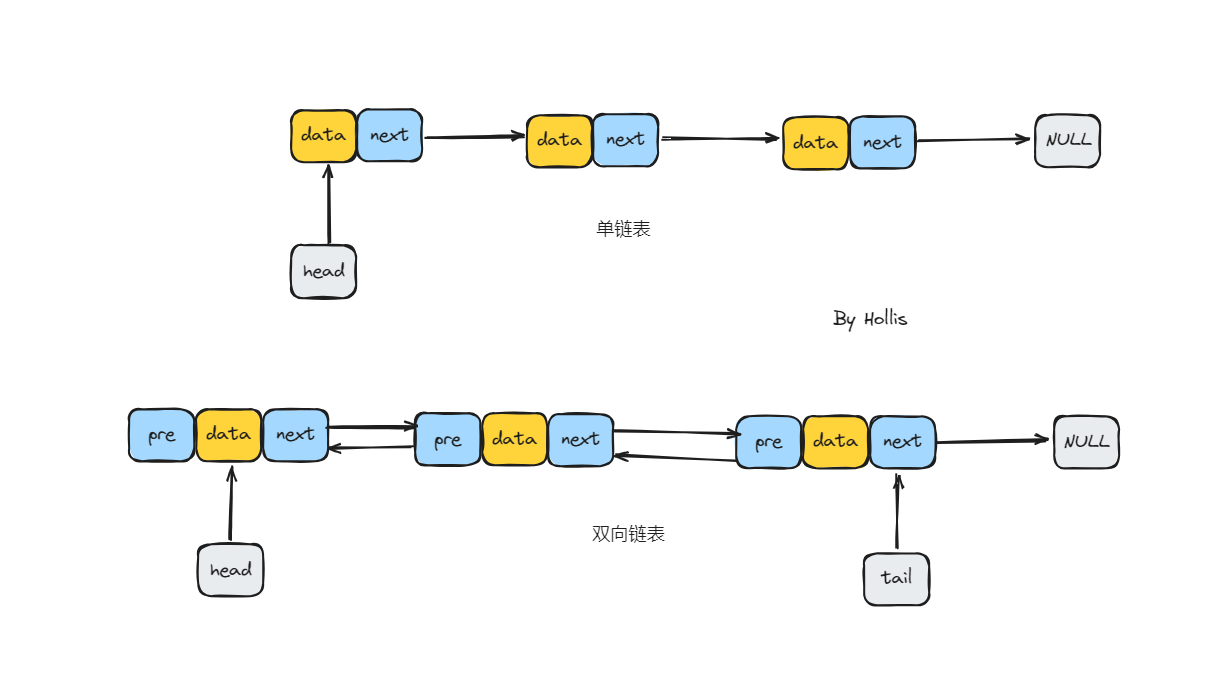
所以,相比于单向链表,双向链表存在以下优势:
- 双向遍历:双向链表可以很方便地正向或反向遍历,这在需要双向访问数据时非常有用。
- 高效的节点插入和删除:在任意位置插入或删除节点时,双向链表可以更为高效地完成操作。因为可以直接访问前一个节点,所以不需要像在单向链表中那样遍历找到前一个节点。
- 灵活的数据操作:双向链表支持更加灵活的数据操作,如从列表尾部添加或移除元素,以及在给定节点前后插入新节点等。
单链表也不是毫无优势,他的内存占用更少,实现更简单。
所以,对于需要双向遍历,或者频繁地在链表中插入和删除节点的场景中,双向链表显然更加合适。
为啥AQS要用双向链表
高效的中断支持
在AQS中,提供了两种基本的获取同步状态的方式,分别对应于支持中断和不支持中断的场景。即acquire和acquireInterruptibly。
acquireInterruptibly这个方法允许线程在做资源竞争时中断。
/**
* Acquires in exclusive mode, ignoring interrupts. Implemented
* by invoking at least once {@link #tryAcquire},
* returning on success. Otherwise the thread is queued, possibly
* repeatedly blocking and unblocking, invoking {@link
* #tryAcquire} until success. This method can be used
* to implement method {@link Lock#lock}.
*
* @param arg the acquire argument. This value is conveyed to
* {@link #tryAcquire} but is otherwise uninterpreted and
* can represent anything you like.
*/
public final void acquire(int arg) {
if (!tryAcquire(arg) &&
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}
/**
* Acquires in exclusive mode, aborting if interrupted.
* Implemented by first checking interrupt status, then invoking
* at least once {@link #tryAcquire}, returning on
* success. Otherwise the thread is queued, possibly repeatedly
* blocking and unblocking, invoking {@link #tryAcquire}
* until success or the thread is interrupted. This method can be
* used to implement method {@link Lock#lockInterruptibly}.
*
* @param arg the acquire argument. This value is conveyed to
* {@link #tryAcquire} but is otherwise uninterpreted and
* can represent anything you like.
* @throws InterruptedException if the current thread is interrupted
*/
public final void acquireInterruptibly(int arg)
throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException();
if (!tryAcquire(arg))
doAcquireInterruptibly(arg);
}
在acquireInterruptibly的执行过程中,执行的是doAcquireInterruptibly方法,这个方法的实现如下:
/**
* Acquires in exclusive interruptible mode.
* @param arg the acquire argument
*/
private void doAcquireInterruptibly(int arg)
throws InterruptedException {
final Node node = addWaiter(Node.EXCLUSIVE);
boolean failed = true;
try {
for (;;) {
final Node p = node.predecessor();
if (p == head && tryAcquire(arg)) {
setHead(node);
p.next = null; // help GC
failed = false;
return;
}
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
throw new InterruptedException();
}
} finally {
if (failed)
cancelAcquire(node);
}
}
在这个方法的finally中执行了一个cancelAcquire的动作,也就是说在acquire的过程中,如果出现了线程中断异常,那么就会执行这个方法,这个方法的代码我就不贴了,太长了,他的主要作用就是将中断的线程节点从AQS同步队列中移除。
而涉及到移除,那么就适合双向链表了,双向链表的每个节点都有prev和next的引用,可以更高效地从队列中移除某个特定的节点(如a b c ,我要删除b的时候,直接找到b的prev也就是a,再找到b的next也就是c,然后把a的next设置为c,c的prev设置为a,就完成了对b的删除)。如果是单向链表就需要从头遍历链表来寻找待删除节点的前驱节点。
高效的挂起支持
当一个线程尝试获取同步状态失败后(例如,尝试获取一个已被其他线程持有的锁),它需要决定接下来的行动。如果直接进入忙等(busy-wait)状态,这将会大量消耗CPU资源,因为线程会在一个循环中不断尝试获取锁,而没有实际的进展。在AQS中可以将线程进行挂起(park)
在执行挂起之前,会通过shouldParkAfterFailedAcquire方法通过检查等待队列中的节点状态来决定一个线程是否应该被挂起。
/**
* Checks and updates status for a node that failed to acquire.
* Returns true if thread should block. This is the main signal
* control in all acquire loops. Requires that pred == node.prev.
*
* @param pred node's predecessor holding status
* @param node the node
* @return {@code true} if thread should block
*/
private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) {
int ws = pred.waitStatus;
if (ws == Node.SIGNAL)
//如果ws为Node.SIGNAL(值为-1),
//这意味着前驱节点已经处于等待状态,期望在释放同步状态时唤醒后继节点。
//在这种情况下,方法可以直接返回true,指示当前线程可以安全地挂起。
return true;
if (ws > 0) {
//如果ws大于0,说明前驱节点已被取消。
//此时,循环向前遍历等待队列,跳过所有已取消的节点,直到找到一个未被取消的节点作为新的前驱节点,并更新相应的链接。
//这个过程是为了维护等待队列的健康状态,移除其中的无效节点。
do {
node.prev = pred = pred.prev;
} while (pred.waitStatus > 0);
pred.next = node;
} else {
//如果前驱节点的等待状态不是SIGNAL(也即,它是0或PROPAGATE),
//则将前驱节点的等待状态更新为SIGNAL。
//这是通过compareAndSetWaitStatus方法完成的,它安全地修改节点的状态,以指示当前节点(node)在释放同步状态时需要被唤醒。
//这里并不立即挂起当前线程,而是返回false,让调用者知道它需要再次尝试获取同步状态,在无法获取时再决定挂起。
compareAndSetWaitStatus(pred, ws, Node.SIGNAL);
}
return false;
}
也就是说,在这个过程中,需要检查当前节点的前驱节点,判断他的状态是不是已经处于等待状态(Node.SIGNAL),如果前驱节点已经是等待状态了,那么自己这个节点也就可以安全的被挂起了。
所以,这里需要获取一个节点的前驱节点,那么就需要用双向链表了,直接获取这个节点的prev就行了。如果是单链表,就得从头开始遍历。
高效的线程判断
AQS中有一个方法,isQueued(Thread thread),他的目的是确定传入的thread线程是否正在AQS的等待队列中等待获取同步状态。
/**
* Returns true if the given thread is currently queued.
*
* <p>This implementation traverses the queue to determine
* presence of the given thread.
*
* @param thread the thread
* @return {@code true} if the given thread is on the queue
* @throws NullPointerException if the thread is null
*/
public final boolean isQueued(Thread thread) {
if (thread == null)
throw new NullPointerException();
for (Node p = tail; p != null; p = p.prev)
if (p.thread == thread)
return true;
return false;
}
他的逻辑挺简单的,就是从队列的队尾开始向前遍历,检查节点所代表的线程是不是传入的线程。
这里之所以从后向前遍历,而没有选择从前向后遍历,主要是因为,在某些场景下(尤其是在使用公平锁时),新加入的线程会被添加到队列尾部,从尾部开始可能更快地找到最近加入的线程,(尽管这种优化在实际效果上可能微乎其微)
但是不管怎么说,从后往前便利确实可能提前返回的概率更大一些,因为需要从后往前遍历,那么就必须得是双向链表,只有双向链表才能方便的获取到前驱节点。
减少并发竞争
不知道大家有没有发现,在AQS中,很多方法的在遍历这个FIFO的队列的时候,是从尾部开始的,如:
public final int getQueueLength() {
int n = 0;
for (Node p = tail; p != null; p = p.prev) {
if (p.thread != null)
++n;
}
return n;
}
/**
* Returns a collection containing threads that may be waiting to
* acquire. Because the actual set of threads may change
* dynamically while constructing this result, the returned
* collection is only a best-effort estimate. The elements of the
* returned collection are in no particular order. This method is
* designed to facilitate construction of subclasses that provide
* more extensive monitoring facilities.
*
* @return the collection of threads
*/
public final Collection<Thread> getQueuedThreads() {
ArrayList<Thread> list = new ArrayList<Thread>();
for (Node p = tail; p != null; p = p.prev) {
Thread t = p.thread;
if (t != null)
list.add(t);
}
return list;
}
/**
* Returns a collection containing threads that may be waiting to
* acquire in exclusive mode. This has the same properties
* as {@link #getQueuedThreads} except that it only returns
* those threads waiting due to an exclusive acquire.
*
* @return the collection of threads
*/
public final Collection<Thread> getExclusiveQueuedThreads() {
ArrayList<Thread> list = new ArrayList<Thread>();
for (Node p = tail; p != null; p = p.prev) {
if (!p.isShared()) {
Thread t = p.thread;
if (t != null)
list.add(t);
}
}
return list;
}
/**
* Returns a collection containing threads that may be waiting to
* acquire in shared mode. This has the same properties
* as {@link #getQueuedThreads} except that it only returns
* those threads waiting due to a shared acquire.
*
* @return the collection of threads
*/
public final Collection<Thread> getSharedQueuedThreads() {
ArrayList<Thread> list = new ArrayList<Thread>();
for (Node p = tail; p != null; p = p.prev) {
if (p.isShared()) {
Thread t = p.thread;
if (t != null)
list.add(t);
}
}
return list;
}
这几个方法都是从尾部开始遍历。官网文档中没有说为什么这么做,网上也几乎没人提为啥这么干,我猜测可能是为了减少对头部节点的竞争。
在高并发环境中,AQS中的队列的头部一定是最频繁访问和修改的区域,因为头部节点是释放同步状态或是被唤醒的线程的首选位置。而把一些不太重要的操作,比如获取排队的线程、获取队列长度等操作,从尾部开始遍历可以减少在头部节点上的竞争,尤其是在执行那些不需要立即修改头部节点状态的遍历操作时。
支持条件队列
上面这篇文章中我们讲过,AQS还支持条件变量,这允许线程在特定条件满足之前挂起。条件队列需要能够从等待队列中移动节点到条件队列,以及反向操作。双向链表使得这种操作更加直接和高效。