
- 首页
- 上一级
- AQS为什么采用双向链表?.md
- AQS是如何实现线程的等待和唤醒的?.md
- AQS的同步队列和条件队列原理?.md
- CAS一定有自旋吗?.md
- CAS在操作系统层面是如何保证原子性的?.md
- CompletableFuture的底层是如何实现的?.md
- CountDownLatch、CyclicBarrier、Semaphore区别?.md
- ForkJoinPool和ThreadPoolExecutor区别是什么?.md
- JDK21中的虚拟线程是怎么回事?.md
- Java是如何判断一个线程是否存活的?.md
- Java线程出现异常,进程为啥不会退出?.md
- LongAdder和AtomicLong的区别?.md
- Thread.sleep(0)的作用是什么?.md
- ThreadLocal为什么会导致内存泄漏?如何解决的?.md
- ThreadLocal的应用场景有哪些?.md
- happens-before和as-if-serial有啥区别和联系?.md
- inta=1是原子性操作吗.md
- run_start、wait_sleep、notify_notifyAll区别_.md
- sychronized是非公平锁吗,那么是如何体现的?.md
- synchronized升级过程中有几次自旋?.md
- synchronized和reentrantLock区别?.md
- synchronized是如何保证原子性、可见性、有序性的?.md
- synchronized是怎么实现的?.md
- synchronized的锁优化是怎样的?.md
- synchronized的锁升级过程是怎样的?.md
- synchronized的锁能降级吗?.md
- synchronized锁的是什么?.md
- volatile是如何保证可见性和有序性的?.md
- volatile能保证原子性吗?为什么?.md
- 三个线程分别顺序打印0-100.md
- 为什么JDK15要废弃偏向锁?.md
- 为什么不建议通过Executors构建线程池.md
- 为什么不能在try-catch中捕获子线程的异常_.md
- 为什么虚拟线程不能用synchronized?.md
- 为什么虚拟线程不要和线程池一起用?.md
- 为什么虚拟线程尽量避免使用ThreadLocal.md
- 什么是AQS的独占模式和共享模式?.md
- 什么是CAS?存在什么问题?.md
- 什么是Java内存模型(JMM)?.md
- 什么是ThreadLocal,如何实现的?.md
- 什么是Unsafe?.md
- 什么是happens-before原则?.md
- 什么是可重入锁,怎么实现可重入锁?.md
- 什么是多线程中的上下文切换?.md
- 什么是守护线程,和普通线程有什么区别?.md
- 什么是并发,什么是并行?.md
- 什么是总线嗅探和总线风暴,和JMM有什么关系?.md
- 什么是死锁,如何解决?.md
- 什么是线程池,如何实现的?.md
- 公平锁和非公平锁的区别?.md
- 创建线程有几种方式?.md
- 到底啥是内存屏障?到底怎么加的?.md
- 如何保证多线程下i++结果正确?.md
- 如何实现主线程捕获子线程异常.md
- 如何对多线程进行编排.md
- 如何理解AQS?.md
- 如何让Java的线程池顺序执行任务?.md
- 并发编程中的原子性和数据库ACID的原子性一样吗?.md
- 有三个线程T1,T2,T3如何保证顺序执行?.md
- 有了CAS为啥还需要volatile?.md
- 有了InheritableThreadLocal为啥还需要TransmittableThreadLocal?.md
- 有了MESI为啥还需要JMM?.md
- 有了synchronized为什么还需要volatile_.md
- 有哪些实现线程安全的方案_.md
- 父子线程之间怎么共享_传递数据?.md
- 线程同步的方式有哪些?.md
- 线程数设定成多少更合适?.md
- 线程是如何被调度的?.md
- 线程有几种状态,状态之间的流转是怎样的?.md
- 线程池的拒绝策略有哪些?.md
- 能不能谈谈你对线程安全的理解?.md
✅ForkJoinPool和ThreadPoolExecutor区别是什么?
典型回答
ForkJoinPool和ExecutorService都是Java中常用的线程池的实现,他们主要在实现方式上有一定的区别,所以也就会同时带来的适用场景上面的区别。
首先在实现方式上,ForkJoinPool 是基于工作窃取(Work-Stealing)算法实现的线程池,ForkJoinPool 中每个线程都有自己的工作队列,用于存储待执行的任务。当一个线程执行完自己的任务之后,会从其他线程的工作队列中窃取任务执行,以此来实现任务的动态均衡和线程的利用率最大化。
ThreadPoolExecutor 是基于任务分配(Task-Assignment)算法实现的线程池,ThreadPoolExecutor 中线程池中有一个共享的工作队列,所有任务都将提交到这个队列中。线程池中的线程会从队列中获取任务执行,如果队列为空,则线程会等待,直到队列中有任务为止。
ForkJoinPool 中的任务通常是一些可以分割成多个子任务的任务,例如快速排序。每个任务都可以分成两个或多个子任务,然后由不同的线程来执行这些子任务。在这个过程中,ForkJoinPool 会自动管理任务的执行、分割和合并,从而实现任务的动态分配和最优化执行。
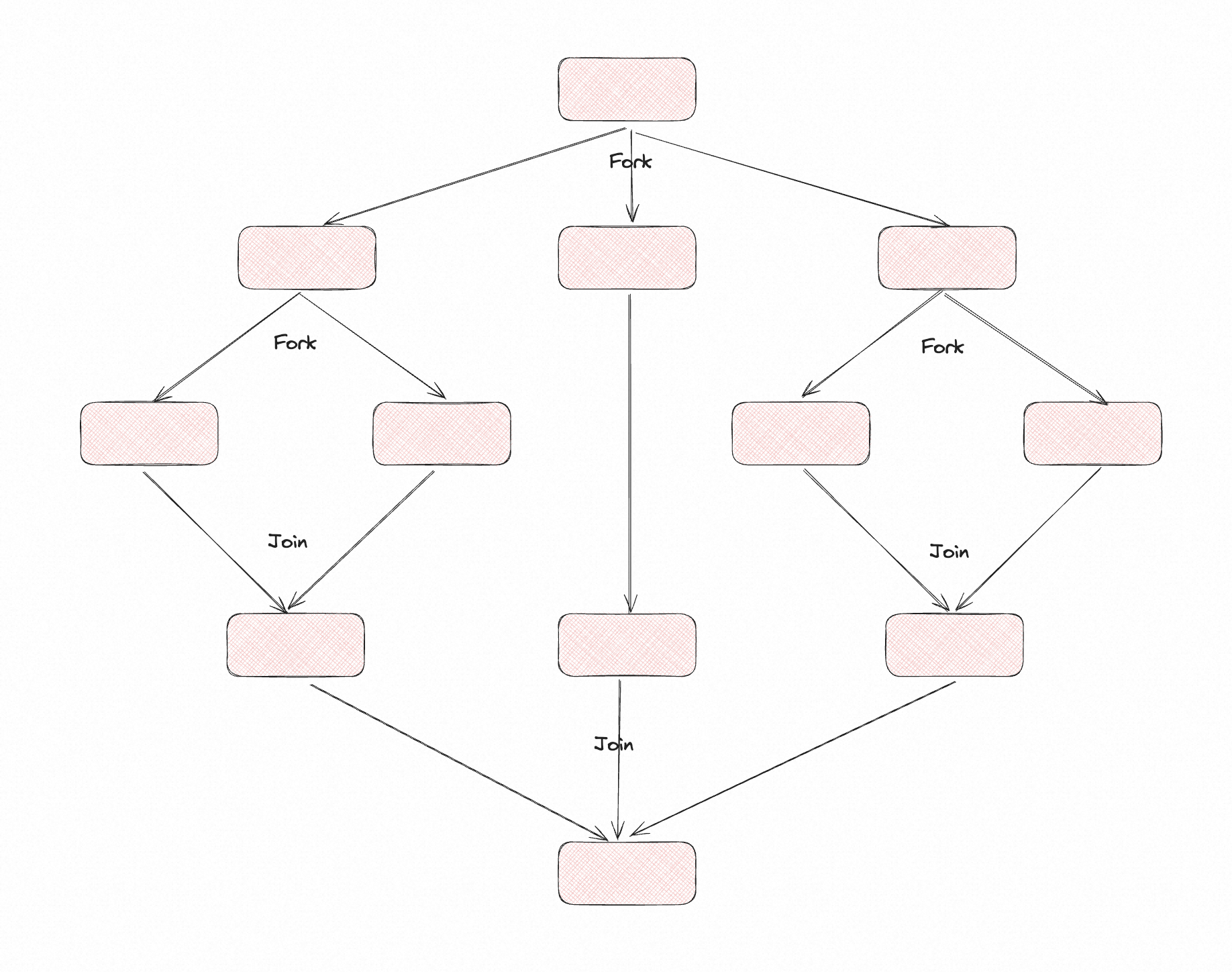
ForkJoinPool 中的工作线程是一种特殊的线程,与普通线程池中的工作线程有所不同。它们会自动地创建和销毁,以及自动地管理线程的数量和调度。这种方式可以降低线程池的管理成本,提高线程的利用率和并行度。
ThreadPoolExecutor 中线程的创建和销毁是静态的,线程池创建后会预先创建一定数量的线程,根据任务的数量动态调整线程的利用率,不会销毁线程。如果线程长时间处于空闲状态,可能会占用过多的资源。
在使用场景上也有区别,ExecutorService 适用于处理较小的、相对独立的任务,任务之间存在一定的依赖关系。例如,处理网络请求、读取文件、执行数据库操作等任务。
ForkJoinPool 适用于于以下场景:
- 大任务分解为小任务:适用于可以递归分解为更小任务的大型任务。ForkJoinPool 通过分而治之的方式,将大任务拆分为小任务,这些小任务可以并行处理。
- 计算密集型任务:对于需要大量计算且能够并行化的任务,ForkJoinPool 是一个理想的选择。它能够有效利用多核处理器的优势来加速处理过程。
- 异构任务并行处理:当任务之间没有或很少有依赖性时,ForkJoinPool 可以帮助并行执行这些任务,从而提高效率。
- 递归算法的并行化:适合于可以用递归方法解决的问题,如快速排序、归并排序、图像处理中的分区算法等。
- 数据聚合任务:在处理需要聚合多个数据源结果的任务时(例如,遍历树结构并聚合结果),ForkJoinPool 提供了有效的方式来并行化这一过程。
递归方法通常涉及到一定程度的依赖性,那么上面的第三、第四点不冲突吗?
异构任务并行处理指的是那些彼此独立的任务,它们可以同时执行而互不干扰。在这种情况下,ForkJoinPool 很适合执行多个不相关的任务,特别是当这些任务没有数据依赖或顺序要求时。
尽管递归算法中的每一步通常都依赖于前一步的结果,但ForkJoinPool 的优势在于能够处理那些可以被分解成多个较小、独立子任务的递归问题。例如,在快速排序中,一旦数组被分割,每个子数组的排序可以独立进行。在这里,虽然总体上存在步骤依赖,但分解后的子任务可以并行执行。
所以,关键在于任务的可分解性和子任务之间的独立性。对于可分解为多个独立子任务的递归问题,ForkJoinPool 是一个强大的工具。而对于那些各个步骤紧密相连、不能有效分解的任务,ForkJoinPool 可能不是最佳选择。
扩展知识
为什么CompletableFuture使用ForkJoinPool
CompletableFuture 使用 ForkJoinPool 而不是 ExecutorService 的原因主要是因为它的执行模型和任务分割方式与 ForkJoinPool 更加匹配。
在 CompletableFuture 中,一个任务可以分割成多个子任务,并且这些子任务之间可以存在依赖关系。而ForkJoinPool 本身就是一种支持任务分割和合并的线程池实现,能够自动地处理任务的拆分和合并。而且,ForkJoinPool 还有一种工作窃取算法,能够自动地调整线程的负载,提高线程的利用率和并行度。
ForkJoinPool 还有一个特点,就是它的线程池大小是动态调整的。当任务比较少时,线程池的大小会自动缩小,从而减少了线程的数量和占用的系统资源。当任务比较多时,线程池的大小会自动增加,从而保证任务能够及时地得到执行。
如果使用 ExecutorService 来执行这些任务,需要手动地创建线程池、任务队列和任务执行策略,并且需要手动地处理任务的拆分和合并,实现起来相对比较复杂。
因此,ForkJoinPool 更加适合 CompletableFuture 的执行模型。
ForkJoinPool使用示例
ForkJoinPool 很适合用于快速排序(Quicksort)算法这种递归操作并行化,原因如下:
- 可分解性:快速排序算法通过选取一个枢纽(pivot)元素将数组分割成两个子数组,一个包含小于枢纽的元素,另一个包含大于枢纽的元素。这种分割过程天然适合并行处理,因为一旦数组被分割,这两个子数组的排序可以独立进行。
- 并行优势:在大数据集上进行快速排序时,ForkJoinPool 可以显著减少排序所需的时间。通过将大数组分割成更小的部分并同时排序,可以有效地利用多核处理器的并行处理能力。
- 减少处理时间:对于大型数组,传统的递归快速排序可能会因递归调用和单线程执行而较慢。ForkJoinPool 提供的并行执行能够显著减少这种情况下的总体处理时间。
- 可伸缩性:ForkJoinPool 能够根据系统的可用资源(如处理器核心数)动态调整并发级别。这意味着它可以在不同的硬件配置上提供良好的性能,特别是在多核处理器上。
下面是一个使用 ForkJoinPool 实现快排的代码:
import java.util.concurrent.RecursiveAction;
import java.util.concurrent.ForkJoinPool;
public class ParallelQuickSort extends RecursiveAction {
private int[] array;
private int left;
private int right;
public ParallelQuickSort(int[] array, int left, int right) {
this.array = array;
this.left = left;
this.right = right;
}
private int partition(int left, int right) {
int pivot = array[right];
int i = left - 1;
for (int j = left; j < right; j++) {
if (array[j] <= pivot) {
i++;
// Swap array[i] and array[j]
int temp = array[i];
array[i] = array[j];
array[j] = temp;
}
}
// Swap array[i+1] and array[right] (or pivot)
int temp = array[i + 1];
array[i + 1] = array[right];
array[right] = temp;
return i + 1;
}
@Override
protected void compute() {
if (left < right) {
int partitionIndex = partition(left, right);
// Parallelize the two subtasks
ParallelQuickSort leftTask = new ParallelQuickSort(array, left, partitionIndex - 1);
ParallelQuickSort rightTask = new ParallelQuickSort(array, partitionIndex + 1, right);
leftTask.fork();
rightTask.fork();
leftTask.join();
rightTask.join();
}
}
public static void parallelQuickSort(int[] array) {
ForkJoinPool pool = new ForkJoinPool();
pool.invoke(new ParallelQuickSort(array, 0, array.length - 1));
}
public static void main(String[] args) {
int[] array = { 12, 35, 87, 26, 9, 28, 7 };
parallelQuickSort(array);
for (int i : array) {
System.out.print(i + " ");
}
}
}
ParallelQuickSort 类继承自 RecursiveAction。在这个类中,compute 方法实现了快速排序的逻辑,包括分区(partition 方法)和递归调用。对于每个递归调用,它创建了一个新的 ParallelQuickSort 实例,并通过 fork 方法将其提交给 ForkJoinPool 以异步执行。
RecursiveAction 是用于创建没有返回值的递归任务的基类。
这个实现通过将快速排序的左右部分分解为独立的任务来实现并行化。在大数据集上,这可以有效利用多核处理器,从而加快排序过程。然而,对于小数组,传统的快速排序可能更高效,因为并行化引入的额外开销可能不值得。