
- 首页
- 上一级
- Arthas统计方法耗时的原理是什么?.md
- CPU飙高问题排查过程(1).md
- CPU飙高问题排查过程(2).md
- Java进程突然挂了,可能是什么原因?.md
- Load飙高问题排查过程.md
- OOM问题排查过程.md
- POI导致内存溢出排查.md
- RT飙高问题排查过程.md
- RocketMQ消费堆积问题排查.md
- Sortaborted问题排查过程.md
- 回表导致慢SQL问题排查.md
- 如何使用jstack分析死锁.md
- 如何排查网络问题?.md
- 慢SQL问题排查.md
- 数据倾斜导致的频繁FullGC问题排查.md
- 数据库CPU被打满排查过程.md
- 数据库死锁问题排查过程.md
- 数据库连接池满排查过程.md
- 服务发布分10批,第一批发完后负载很高后面恢复正常,如何处理?.md
- 服务器突然ssh连不上了,可能是什么问题?.md
- 死循环会导致CPU使用率升高吗?为什么?.md
- 死锁会导致CPU使用率升高吗?为什么?.md
- 程序运行期发生ClassNotFoundException可能是什么原因?.md
- 频繁FullGC问题排查(2).md
- 频繁FullGC问题排查.md
✅回表导致慢 SQL 问题排查
问题发现
线上突然疯狂报警,某个接口的调用成功率暴跌,失败数突增。
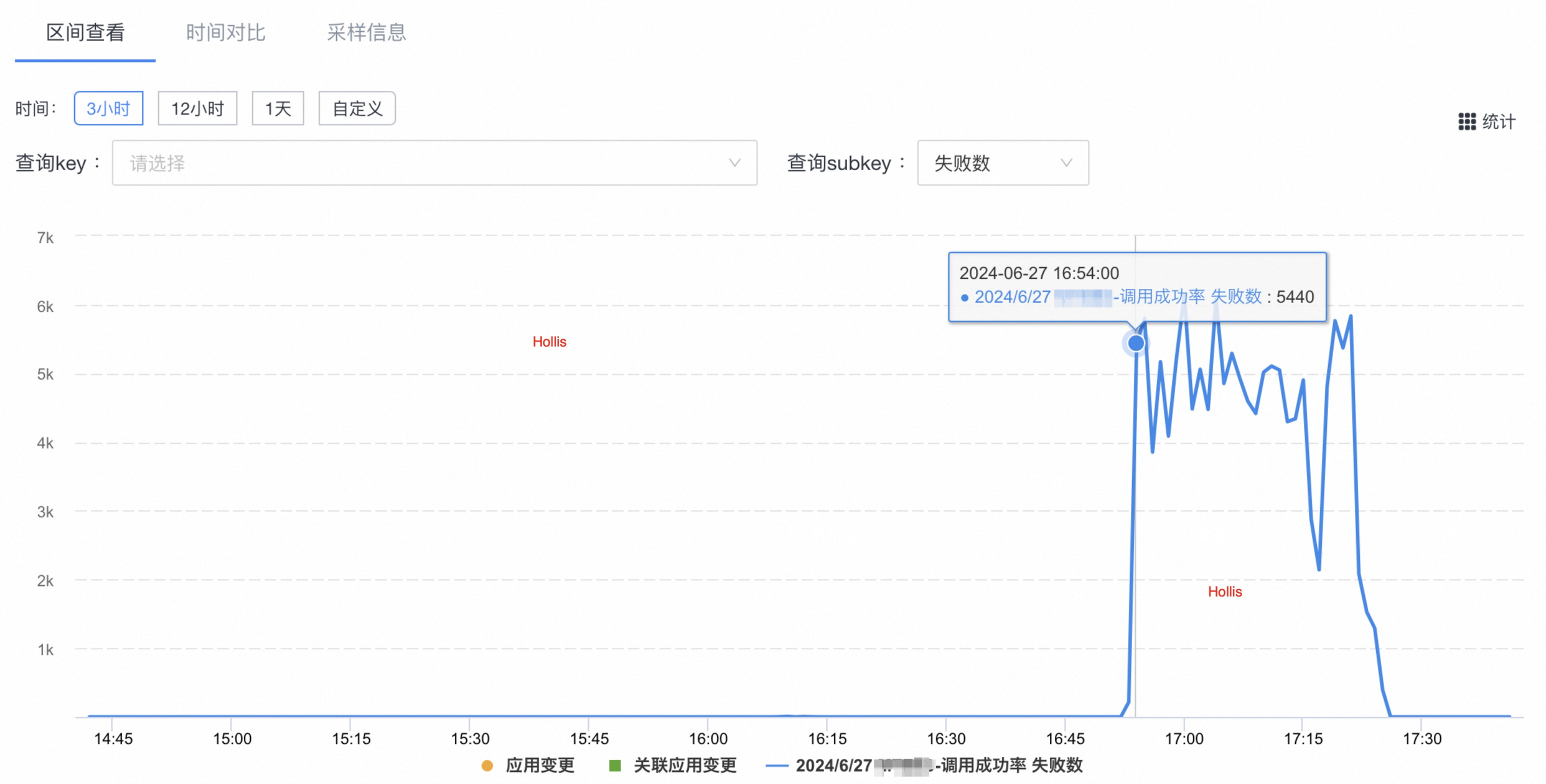
经过一番排查,发现底层数据库CPU已经被拉到了100%,在进行了紧急扩容后,开始进行根因分析。
问题排查
通过数据库的诊断工具,发现有一个慢SQL,执行了很多次,并且耗时比较长,找到的SQL具体如下:
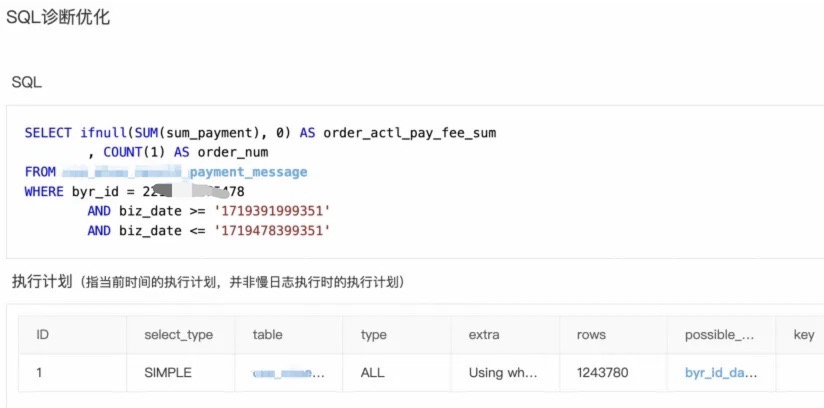
这个用户确实是一个大买家、表中一共100多万条数据,他自己就有几十万单(新的业务模式,之前也没见过)
并且在分析过程中,发现这个 SQL 有的时候走索引,有的时候不走索引,并且走不走索引都很慢。于是看一下成本消耗到底在哪里。
EXPLAIN FORMAT=json
SELECT ifnull(SUM(sum_payment), 0) AS order_actl_pay_fee_sum
, COUNT(1) AS order_num
FROM xxxx_payment_message
WHERE byr_id = 221xxxx478
AND biz_date >= '1719391999351'
AND biz_date <= '1719478399351';
得到的结果如下:
{
"query_block": {
"select_id": 1,
"cost_info": {
"query_cost": "139147.15" # 总成本
},
"table": {
"table_name": "xxxx_payment_message",
"access_type": "ALL",
"possible_keys": [
"byr_id_date_index",
"biz_date_index"
],
"rows_examined_per_scan": 1364869,
"rows_produced_per_join": 448231,
"filtered": "32.84",
"cost_info": {
"read_cost": "94323.95", # IO Cost(Engine Cost)
"eval_cost": "44823.20", # CPU Cost(Server Cost)
"prefix_cost": "139147.15", # 总成本
"data_read_per_join": "458M"
},
"used_columns": [
"byr_id",
"biz_date",
"sum_payment"
]
}
}
}
这条 SQL 不走索引,实际耗时675ms,预估扫描行数1374150行 ,cbo为139147.15。
在看下以下这个SQL:
()()()()()()()()搜索是EXPLAIN FORMAT=json
SELECT ifnull(SUM(sum_payment), 0) AS order_actl_pay_fee_sum
, COUNT(1) AS order_num
FROM xxxx_payment_message force index(byr_id_date_index)
WHERE byr_id = 2217618275478
AND biz_date >= '1719392683881'
AND biz_date <= '1719479083881';
得到结果如下:
{
"query_block": {
"select_id": 1,
"cost_info": {
"query_cost": "201704.66"# 总成本
},
"table": {
"table_name": "xxxx_payment_message",
"access_type": "range",
"possible_keys": [
"byr_id_date_index"
],
"key": "byr_id_date_index",
"used_key_parts": [
"byr_id",
"biz_date"
],
"key_length": "18",
"rows_examined_per_scan": 448232,
"rows_produced_per_join": 448232,
"filtered": "100.00",
"cost_info": {
"read_cost": "156881.46",# IO Cost(Engine Cost)
"eval_cost": "44823.20",# CPU Cost(Server Cost)
"prefix_cost": "201704.66",# 总成本
"data_read_per_join": "458M"
},
"used_columns": [
"byr_id",
"biz_date",
"sum_payment"
]
}
}
}
这个 SQL 走索引,执行耗时709ms,扫描行数448232行,cbo为201704.66
两条SQL,一条走索引,一条不走,耗时都在700ms 左右,这说明优化器确实在走与不走索引之间摇摆,并且摇摆的也不无道理,毕竟即使走了索引也没有快到哪里去。
因为我们介绍过 MySQL是基于cbo的优化器,会对每一个索引计算成本消耗,选择成本最低的索引,但如果通过主键进行全表扫描的成本消耗比二级索引要低,那就会选择全表扫描。
这里就开始疑惑了,为啥走索引竟然比全表扫描还要低呢?分析上面的第一个执行计划的结果,我们发现成本这里,主要的消耗在 IO 上面,而 IO 的成本主要是从内存读取以及从磁盘读取数据的消耗,而走了索引的竟然消耗也这么高,不太科学。
"cost_info": {
"read_cost": "94323.95", # IO Cost(Engine Cost)
"eval_cost": "44823.20", # CPU Cost(Server Cost)
"prefix_cost": "139147.15", # 总成本
"data_read_per_join": "458M"
},
于是继续去排查索引和 SQL 的情况(其实早就应该查这个,只不过前面一直在看为啥同样的 SQL 有的走索引,有的不走),最终发现 SQL 虽然命中了索引,但是还是需要回表,因为我们的索引中只包含了byrid和 bizdate这两个字段,而 sum_payment 并不在里面,这就意味着每次查询都需要回表。
所以即使走了索引,他的IO消耗也很高,主要都在回表上。
问题解决
问题定位到了,解决就简单了。
直接把sumpayment也加到byrid和 biz_date这的索引中,组成一个联合索引即可,减少回表次数。
优化后,这个大买家的查询 SQL 的执行耗时在200ms 以内就能返回,io 成本也降到了原来的1/3左右。