
- 首页
- 上一级
- Arthas统计方法耗时的原理是什么?.md
- CPU飙高问题排查过程(1).md
- CPU飙高问题排查过程(2).md
- Java进程突然挂了,可能是什么原因?.md
- Load飙高问题排查过程.md
- OOM问题排查过程.md
- POI导致内存溢出排查.md
- RT飙高问题排查过程.md
- RocketMQ消费堆积问题排查.md
- Sortaborted问题排查过程.md
- 回表导致慢SQL问题排查.md
- 如何使用jstack分析死锁.md
- 如何排查网络问题?.md
- 慢SQL问题排查.md
- 数据倾斜导致的频繁FullGC问题排查.md
- 数据库CPU被打满排查过程.md
- 数据库死锁问题排查过程.md
- 数据库连接池满排查过程.md
- 服务发布分10批,第一批发完后负载很高后面恢复正常,如何处理?.md
- 服务器突然ssh连不上了,可能是什么问题?.md
- 死循环会导致CPU使用率升高吗?为什么?.md
- 死锁会导致CPU使用率升高吗?为什么?.md
- 程序运行期发生ClassNotFoundException可能是什么原因?.md
- 频繁FullGC问题排查(2).md
- 频繁FullGC问题排查.md
✅数据倾斜导致的频繁FullGC问题排查
问题发现
线上兼容系统报警,提示有频繁的FullGC以及GC耗时问题比较严重。
问题定位
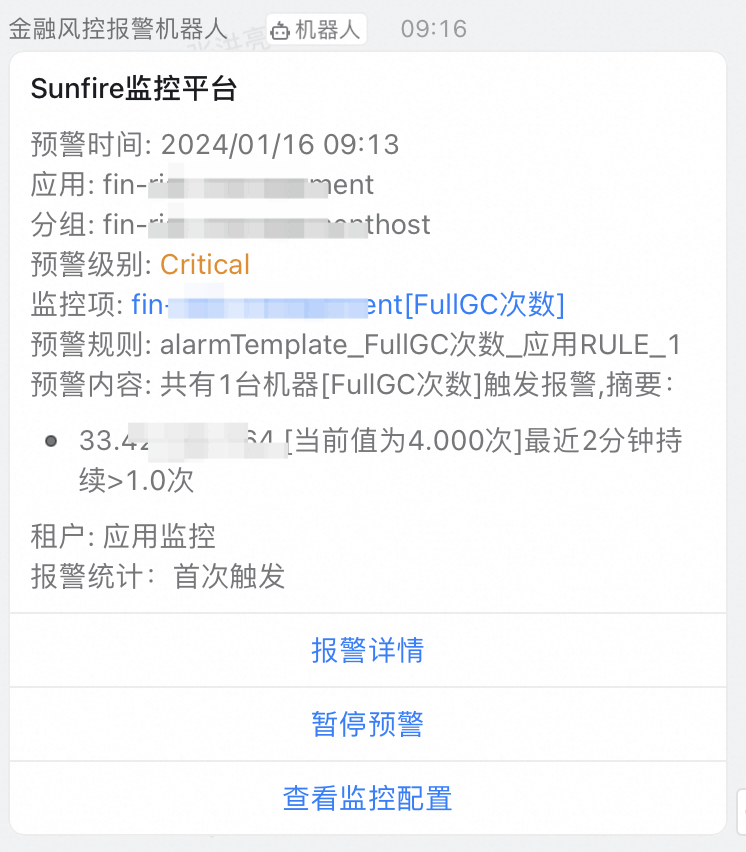
在收到FullGC报警之后,登录到内部的监控系统,看一下集群整体的GC情况(如果没有这样的监控系统,可以去机器上查看GC日志):

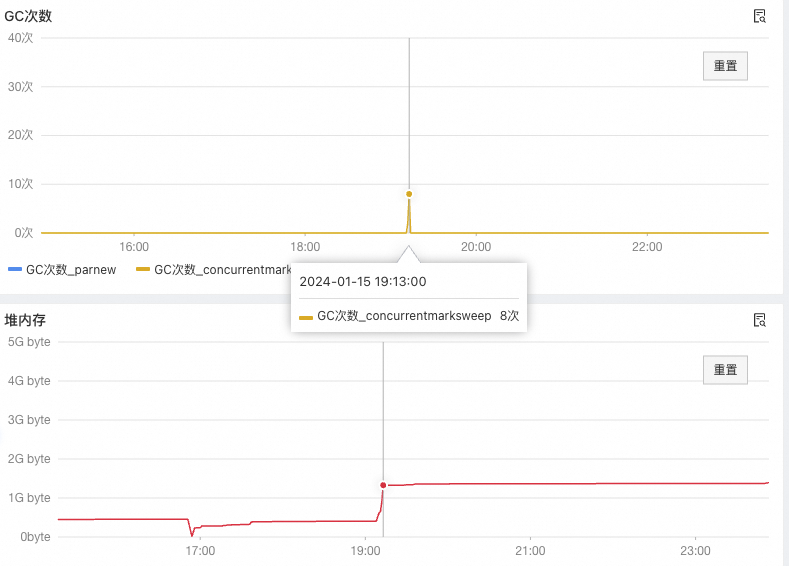
从图中可以看到,从大概9:03分开始,对内存的老年代就一直在涨,并且在9:13的时候发生了很多次fullGC。
这时候,第一时间去把堆dump下来了,我先在GC前做了一次Dump,然后再做了一次GC,然后做了一次Dump,发现GC前的Dump中很多String占用了比较多的内存,但是GC后就都被回收了。
然后去看这些字符串都是啥,但是很遗憾,没看出什么特别有价值的东西,都是一些游离的字符串(一方面通过堆dump发现他们不可达,另外发现FullGC后就直接回收了)
这时候就在分析,为啥会发生这样的情况。于是我怀疑,可能是因为在9:00-9:20这段时间,请求量比较大,创建了很多对象分配到年轻代,但是年轻代不够了,就被分配到老年代。然后老年代一直在GC,但是因为同时又有大量的操作导致对象也在不断往老年代去。所以看上去老年代在9:13分左右的GC效果并不明显。
为了验证这个猜想,同时看了下年轻代的情况,Eden区没啥明显变化,但是Survivor区的增长比较大:
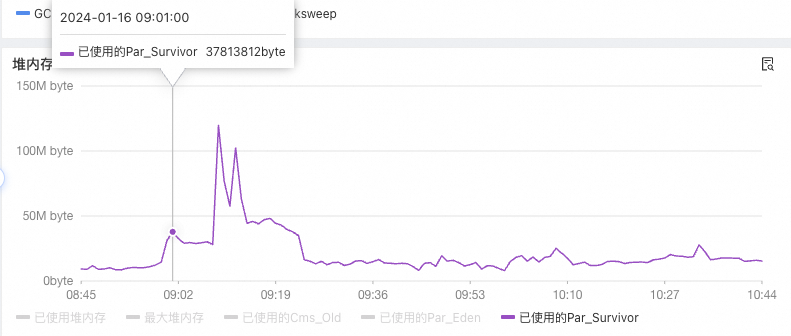
于是感觉这个方向是靠谱的,大概率是这段时间的请求量太大了,导致很多对象被分配到老年代,然后触发了很多次FullGC。
于是开始看系统监控,找这段时间有没有哪些接口或者请求的量比较大。
1、先是翻了我们的RPC接口的调用量监控,发现并无异常。
2、继续翻了MQ的消费量监控,发现并无异常。
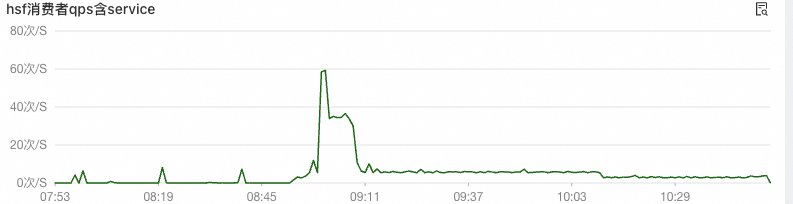
3、查看对外部接口的调用量监控,发现有一个接口的调用量QPS比较高。
4、查看TDDL的QPS(TDDL是阿里内部的数据库访问中间件,可以简单认为是数据库连接池)飙高明显。
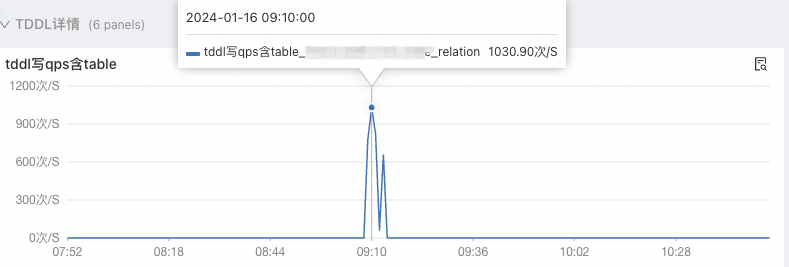
结合这两个现象,一个是具体哪个接口调用量变大了,一个是哪张表的写操作变多了。而且时间也刚好对得上,于是就继续分析。
开始找这部分代码的调用链,发现是一个定时任务,扫表进行数据操作的。而且时间也对得上,每小时执行一次,基本上是在整点开始执行,大概15分钟执行完。
这里交代一下背景,我们的定时任务是分布式任务,也就是说比如有10000条数据,会有10台机器并发去扫描这些数据来处理。
这里奇怪的是只有一台机器有这个FullGC以及堆被干满的情况,这不应该啊。于是我开始逐台机器查看他最近12小时的堆内存情况。
还真让我发现了一个规律,那就是在不同的时间点,都会有其中某台机器的内存升高,有的时候会有FullGC,有的时候没有,而且基本都是在整点左右开始,并且也伴随着前面发现的TDDL和接口的调用量飙升。
以下是另外一台机器在前一天19点左右的堆内存及GC情况。
再来总结一下现象:
1、每个整点开始,会有一个扫表任务开始执行,任务是分布式,多台机器并发开始执行。
2、任务开始执行后,会有某台机器的老年代内存被干满,导致频繁的FullGC
3、GC是有效果的,说明这些对象都是垃圾对象。可以被回收的。那就是因为年轻代放不下了导致的,而不是内存泄漏。
到这里,聪明的我马上想到了问题可能出在哪了。(机智脸
然后我开始验证我的想法,找到一个整点时间点,然后去看这个整点之后的15分钟内,有堆内催增长的机器,和没有堆内存增长(或者增长不明显)的机器,对比日志。
假设:9:00是11.11.11.11这台机器FullGC了, 10:00 是22.22.22.22这台机器FullGC了。
那么就这么对比:
11.11.11.11机器在9:00 - 10:00之间的日志,和,11.11.11.11机器在8:00-9:00之间的日志对比。
22.22.22.22机器在9:00 - 10:00之间的日志,和,22.22.22.22机器在10:00-11:00之间的日志对比。
然后我就发现了问题:
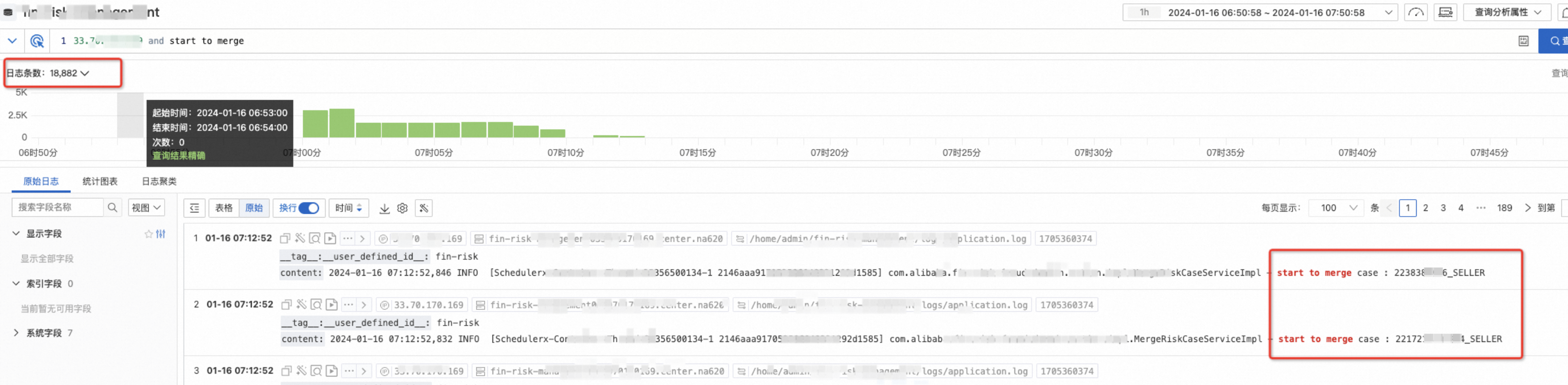
11.11.11.11机器在9:00 - 10:00之间和22.22.22.22机器在10:00-11:00之间扫描的数据范围是一样的,都是用户ID以22作为开头的数据。
因为我们是分布式任务扫表,为了扫表不重复,所以会根据用户ID的前两位进行分段,然后随机给不同的机器去扫描不同的前缀的用户。
刚好22开头的用户太多(数据严重倾斜)导致分到这段的机器就要处理大量数据,处理过程中会创建很多对象,导致内存被占用。然后因为随机分的,所以不同的时段会有不同的机器内存被干满。
可以看到22开头的明显比别的多很多:

如下图,是一台6:00-7:00之间有FullGC的机器的日志情况:
问题解决
问题定位到了,解决就容易了,想办法让倾斜的数据在分布式任务扫表的时候均分就行了。有几个办法:
1、之前是按照用户ID前两位分的,那么就再分的细一点,按照前3位分一下。
2、不再按照用户ID分,而是按照主键ID进行分段。(最开始没用这个方案是因为待扫描数据并不连续,区间长度不太好掌握,还有个重要原因就是需要在SQL中针对相同用户做数据聚合。)