
- 首页
- 上一级
- Arrays.sort是使用什么排序算法实现的?.md
- BigDecimal(double)和BigDecimal(String)有什么区别?.md
- BigDecimal和Long表示金额哪个更合适,怎么选择?.md
- ClassNotFoundException和NoClassDefFoundError的区别是什么?.md
- JDK9中对字符串的拼接做了什么优化?.md
- JDK新版本中都有哪些新特性?.md
- Java中Timer实现定时调度的原理是什么?.md
- Java中创建对象有哪些种方式.md
- Java中异常分哪两类,有什么区别?.md
- Java中有了基本类型为什么还需要包装类?.md
- Java中的static都能用来修饰什么?.md
- Java中的枚举有什么特点和好处.md
- Java和C++主要区别有哪些?各有哪些优缺点?.md
- Java序列化的原理是啥.md
- Java是值传递还是引用传递?.md
- Java注解的作用是啥.md
- Java的动态代理如何实现?.md
- Lambda表达式是如何实现的?.md
- RPC接口返回中,使用基本类型还是包装类?.md
- SimpleDateFormat是线程安全的吗?使用时应该注意什么?.md
- Stream的并行流一定比串行流更快吗?.md
- Stringa=_ab_;Stringb=_a_+_b_;a==b吗?.md
- Stringstr=newString(_hollis_)创建了几个对象?.md
- String、StringBuilder和StringBuffer的区别?.md
- String中intern的原理是什么?.md
- String为什么设计成不可变的?.md
- String是如何实现不可变的?.md
- String有长度限制吗?是多少?.md
- char能存储中文吗?.md
- finally中代码一定会执行吗?.md
- final、finally、finalize有什么区别.md
- serialVersionUID有何用途_如果没定义会有什么问题?.md
- try中returnA,catch中returnB,finally中returnC,最终返回值是什么?.md
- while(true)和for(;;)哪个性能好?.md
- 为什么JDK9中把String的char[]改成了byte[]?.md
- 为什么Java不支持多继承?.md
- 为什么Java中的main方法必须是publicstaticvoid的?.md
- 为什么不建议使用异常控制业务流程.md
- 为什么不能用BigDecimal的equals方法做等值比较?.md
- 为什么不能用浮点数表示金额?.md
- 为什么对Java中的负数取绝对值结果不一定是正数?.md
- 为什么建议多用组合少用继承?.md
- 为什么建议自定义一个无参构造函数.md
- 为什么这段代码在JDK不同版本中结果不同.md
- 什么是AIO、BIO和NIO?.md
- 什么是SPI,和API有啥区别.md
- 什么是UUID,能保证唯一吗?.md
- 什么是反射机制?为什么反射慢?.md
- 什么是序列化与反序列化.md
- 什么是泛型?有什么好处?.md
- 什么是深拷贝和浅拷贝?.md
- 什么是类型擦除?.md
- 以下关于异常处理的代码有哪些问题.md
- 你知道fastjson的反序列化漏洞吗.md
- 如何理解Java中的多态?.md
- 如何理解面向对象和面向过程?.md
- 字符串常量是什么时候进入到字符串常量池的?.md
- 常见的字符编码有哪些?有什么区别?.md
- 怎么修改一个类中的private修饰的String参数的值.md
- 接口和抽象类的区别,如何选择?.md
- 有了equals为啥需要hashCode方法?.md
- 泛型中KTVE?Object等分别代表什么含义。.md
- 泛型中上下界限定符extends和super有什么区别?.md
- 现在JDK的最新版本是什么?.md
- 说几个常见的语法糖?.md
✅String str=new String("hollis")创建了几个对象?
典型回答
创建的对象数应该是1个或者2个。
首先要清楚什么是对象?
Java是一种面向对象的语言,而Java对象在JVM中的存储也是有一定的结构的,在HotSpot虚拟机中,存储的形式就是oop-klass model,即Java对象模型。我们在Java代码中,使用new创建一个对象的时候,JVM会创建一个instanceOopDesc对象,这个对象中包含了两部分信息,对象头以及元数据。对象头中有一些运行时数据,其中就包括和多线程相关的锁的信息。元数据其实维护的是指针,指向的是对象所属的类的instanceKlass。
这才叫对象。其他的,一概都不叫对象。
那么不管怎么样,一次new的过程,都会在堆上创建一个对象,那么就是起码有一个对象了。至于另外一个对象,到底有没有要看具体情况了。
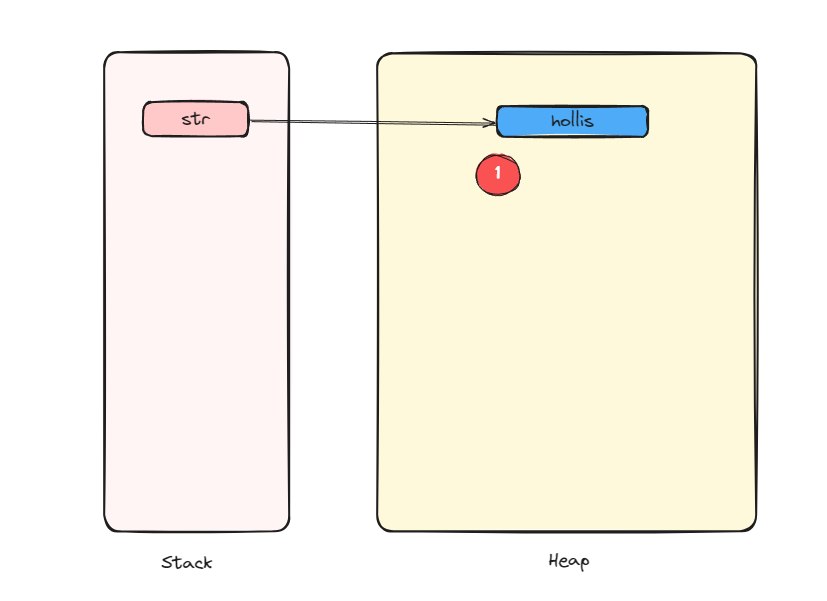
另外这一个对象就是常量池中的字符串常量,这个字符串其实是类编译阶段就进到Class常量池的,然后在运行期,字符串常量在第一次被调用(准确的说是ldc指令)的时候,进行解析并在字符串池中创建对应的String实例的。
在运行时常量池中,也并不是会立刻被解析成对象,而是会先以JVMCONSTANTUnresolveString_info的形式驻留在常量池。在后面,该引用第一次被LDC指令执行到的时候,就尝试在堆上创建字符串对象,并将对象的引用驻留在字符串常量池中。
通过看上面的过程,你也能发现,这个过程的触发条件是我们没办法决定的,问题的题干中也没提到。有可能执行这段代码的时候是第一次LDC指令执行,也许在前面就执行过了。
所以,如果是第一次执行,那么就是会同时创建两个对象。一个字符串常量引用指向的对象,一个我们new出来的对象。
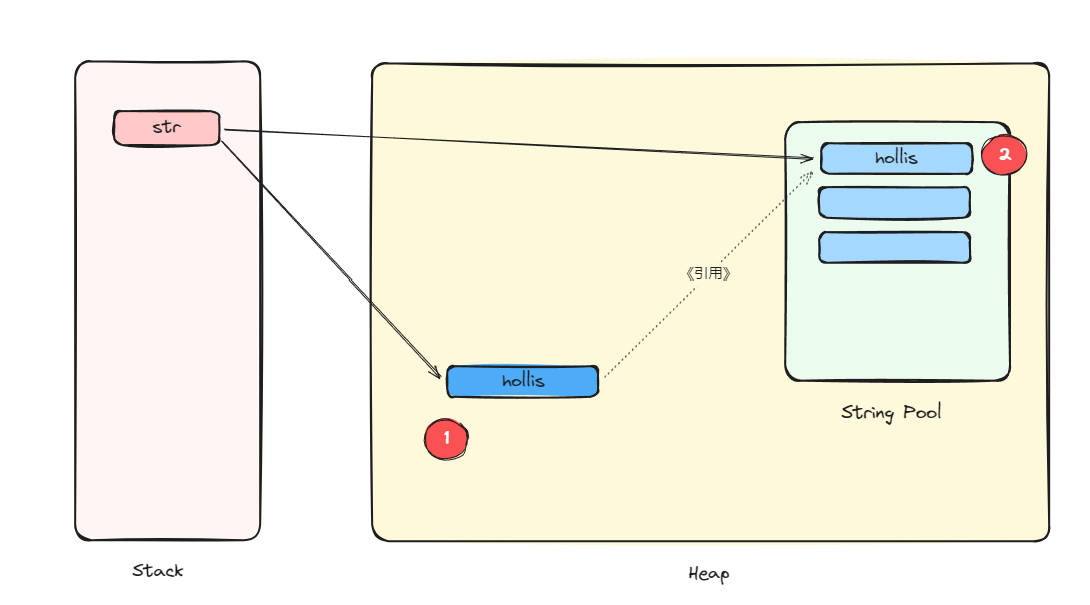
如果不是第一次执行,那么就只会创建我们自己new出来的对象。
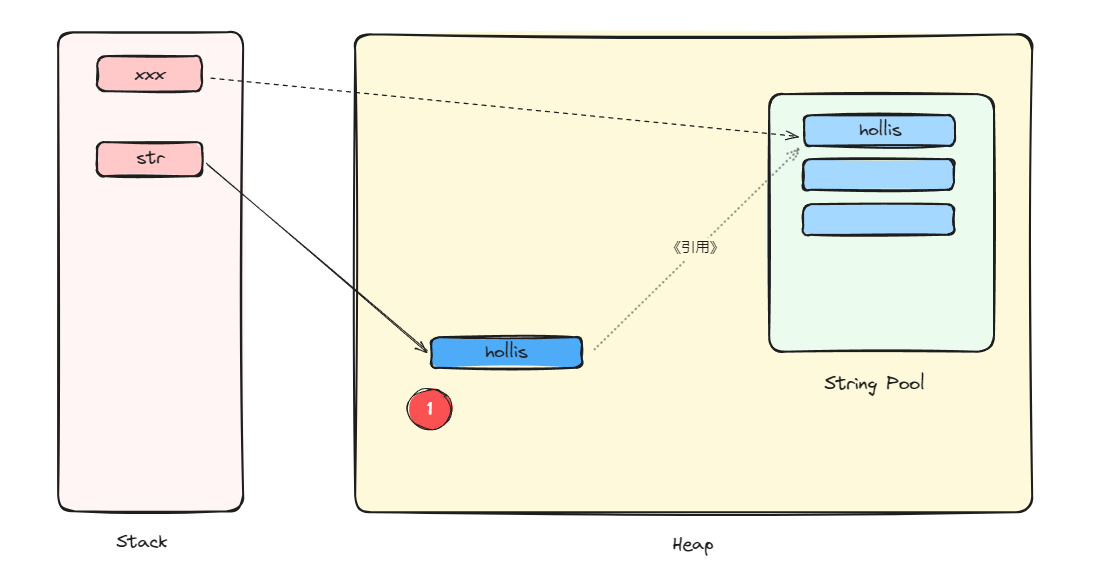
至于有人说什么在字符串池内还有在栈上还有一个引用对象,你听听这说法,引用就是引用。别往对象上面扯。
扩展知识
字面量和运行时常量池
JVM为了提高性能和减少内存开销,在实例化字符串常量的时候进行了一些优化。为了减少在JVM中创建的字符串的数量,字符串类维护了一个字符串常量池。
在JVM运行时区域的方法区中,有一块区域是运行时常量池,主要用来存储编译期生成的各种字面量和符号引用。
了解Class文件结构或者做过Java代码的反编译的朋友可能都知道,在java代码被javac编译之后,文件结构中是包含一部分Constant pool的。比如以下代码:
public static void main(String[] args) {
String s = "Hollis";
}
经过编译后,常量池内容如下:
Constant pool:
#1 = Methodref #4.#20 // java/lang/Object."<init>":()V
#2 = String #21 // Hollis
#3 = Class #22 // StringDemo
#4 = Class #23 // java/lang/Object
...
#16 = Utf8 s
..
#21 = Utf8 Hollis
#22 = Utf8 StringDemo
#23 = Utf8 java/lang/Object
上面的Class文件中的常量池中,比较重要的几个内容:
#16 = Utf8 s
#21 = Utf8 Hollis
#22 = Utf8 StringDemo
上面几个常量中,s就是前面提到的符号引用,而Hollis就是前面提到的字面量。而Class文件中的常量池部分的内容,会在运行期被运行时常量池加载进去。关于字面量,详情参考Java SE Specifications
intern
编译期生成的各种字面量和符号引用是运行时常量池中比较重要的一部分来源,但是并不是全部。那么还有一种情况,可以在运行期向运行时常量池中增加常量。那就是String的intern方法。
当一个String实例调用intern()方法时,Java查找常量池中是否有相同Unicode的字符串常量,如果有,则返回其的引用,如果没有,则在常量池中增加一个Unicode等于str的字符串并返回它的引用;
intern()有两个作用,第一个是将字符串字面量放入常量池(如果池没有的话),第二个是返回这个常量的引用。
intern的正确用法
不知道,你有没有发现,在String s3 = new String("Hollis").intern();中,其实intern是多余的?
因为就算不用intern,Hollis作为一个字面量也会被加载到Class文件的常量池,进而加入到运行时常量池中,为啥还要多此一举呢?到底什么场景下才需要使用intern呢?
在解释这个之前,我们先来看下以下代码:
String s1 = "Hollis";
String s2 = "Chuang";
String s3 = s1 + s2;
String s4 = "Hollis" + "Chuang";
在经过反编译后,得到代码如下:
String s1 = "Hollis";
String s2 = "Chuang";
String s3 = (new StringBuilder()).append(s1).append(s2).toString();
String s4 = "HollisChuang";
可以发现,同样是字符串拼接,s3和s4在经过编译器编译后的实现方式并不一样。s3被转化成StringBuilder及append,而s4被直接拼接成新的字符串。
如果你感兴趣,你还能发现,String s3 = s1 + s2; 经过编译之后,常量池中是有两个字符串常量的分别是 Hollis、Chuang(其实Hollis和Chuang是String s1 = "Hollis";和String s2 = "Chuang";定义出来的),拼接结果HollisChuang并不在常量池中。
究其原因,是因为常量池要保存的是已确定的字面量值。也就是说,对于字符串的拼接,纯字面量和字面量的拼接,会把拼接结果作为常量保存到字符串池。
如果在字符串拼接中,有一个参数是非字面量,而是一个变量的话,整个拼接操作会被编译成StringBuilder.append,这种情况编译器是无法知道其确定值的。只有在运行期才能确定。
那么,有了这个特性了,intern就有用武之地了。那就是很多时候,我们在程序中得到的字符串是只有在运行期才能确定的,在编译期是无法确定的,那么也就没办法在编译期被加入到常量池中。
这时候,对于那种可能经常使用的字符串,使用intern进行定义,每次JVM运行到这段代码的时候,就会直接把常量池中该字面值的引用返回,这样就可以减少大量字符串对象的创建了。
如一深入解析String#intern文中举的一个例子:
static final int MAX = 1000 * 10000;
static final String[] arr = new String[MAX];
public static void main(String[] args) throws Exception {
Integer[] DB_DATA = new Integer[10];
Random random = new Random(10 * 10000);
for (int i = 0; i < DB_DATA.length; i++) {
DB_DATA[i] = random.nextInt();
}
long t = System.currentTimeMillis();
for (int i = 0; i < MAX; i++) {
arr[i] = new String(String.valueOf(DB_DATA[i % DB_DATA.length])).intern();
}
System.out.println((System.currentTimeMillis() - t) + "ms");
System.gc();
}
在以上代码中,我们明确的知道,会有很多重复的相同的字符串产生,但是这些字符串的值都是只有在运行期才能确定的。所以,只能我们通过intern显示的将其加入常量池,这样可以减少很多字符串的重复创建。