
- 首页
- 上一级
- Redis5.0中的Stream是什么?.md
- RedisCluster中使用事务和lua有什么限制?.md
- Redisson中为什么要废弃RedLock,该用啥?.md
- Redisson和Jedis有啥区别?如何选择?.md
- Redisson如何保证解锁的线程一定是加锁的线程?.md
- Redisson的lock和tryLock有什么区别?.md
- Redisson的watchdog什么情况下可能会失效?.md
- Redisson的watchdog机制是怎么样的?.md
- Redis与Memcached有什么区别?.md
- Redis中key过期了一定会立即删除吗.md
- Redis中有一批key瞬间过期,为什么其它key的读写效率会降低?.md
- Redis中的Zset是怎么实现的?.md
- Redis中的setnx命令为什么是原子性的.md
- Redis为什么被设计成是单线程的?.md
- Redis为什么要自己定义SDS?.md
- Redis为什么这么快?.md
- Redis使用什么协议进行通信?.md
- Redis如何实现发布_订阅?.md
- Redis如何实现延迟消息?.md
- Redis如何高效安全的遍历所有key.md
- Redis实现分布锁的时候,哪些问题需要考虑?.md
- Redis支持哪几种数据类型?.md
- Redis是AP的还是CP的?.md
- Redis的Key和Value的设计原则有哪些?.md
- Redis的事务和Lua之间有哪些区别?.md
- Redis的事务机制是怎样的?.md
- Redis的内存淘汰策略是怎么样的?.md
- Redis的持久化机制是怎样的?.md
- Redis的虚拟内存机制是什么?.md
- Redis的过期策略是怎么样的?.md
- watchdog一直续期,那客户端挂了怎么办?.md
- watchdog解锁失败,会不会导致一直续期下去?.md
- 为什么Lua脚本可以保证原子性?.md
- 为什么Redis6.0引入了多线程?.md
- 为什么Redis不支持回滚?.md
- 为什么Redis设计成单线程也能这么快?.md
- 为什么ZSet既能支持高效的范围查询,还能以O(1)复杂度获取元素权重值?.md
- 为什么需要延迟双删,两次删除的原因是什么?.md
- 什么情况下会出现数据库和缓存不一致的问题?.md
- 什么是GEO,有什么用?.md
- 什么是RedLock,他解决了什么问题?.md
- 什么是Redis的Pipeline,和事务有什么区别?.md
- 什么是Redis的数据分片?.md
- 什么是Redis的渐进式rehash.md
- 什么是大Key问题,如何解决?.md
- 什么是热Key问题,如何解决热key问题.md
- 什么是缓存击穿、缓存穿透、缓存雪崩?.md
- 介绍一下Redis的集群模式?.md
- 介绍下Redis集群的脑裂问题?.md
- 如何在RedisCluster中执行lua脚本?.md
- 如何基于Redisson实现一个延迟队列.md
- 如何基于Redis实现滑动窗口限流?.md
- 如何用Redisson实现分布式锁?.md
- 如何用Redis实现乐观锁?.md
- 如何用SETNX实现分布式锁?.md
- 如何用setnx实现一个可重入锁?.md
- 如何解决Redis和数据库的一致性问题?.md
- 对于Redis的操作,有哪些推荐的BestPractices?.md
- 除了做缓存,Redis还能用来干什么?.md
✅Redis中的Zset是怎么实现的?
典型回答
ZSet(也称为Sorted Set)是Redis中的一种特殊的数据结构,它内部维护了一个有序的字典,这个字典的元素中既包括了一个成员(member),也包括了一个double类型的分值(score)。这个结构可以帮助用户实现记分类型的排行榜数据,比如游戏分数排行榜,网站流行度排行等。
Redis中的ZSet在实现中,有多种结构,大类的话有两种,分别是ziplist(压缩列表)和skiplist(跳跃表),但是这只是以前,在Redis 5.0中新增了一个listpack(紧凑列表)的数据结构,这种数据结构就是为了替代ziplist的,而在之后Redis 7.0的发布中,在Zset的实现中,已经彻底不在使用zipList了。
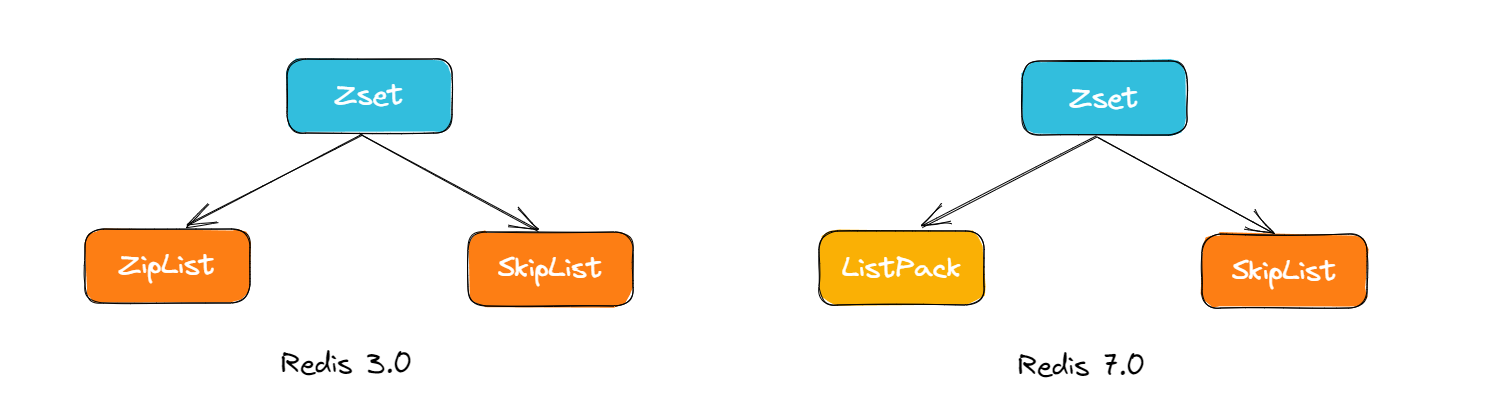
当ZSet的元素数量比较少时,Redis会采用ZipList(ListPack)来存储ZSet的数据。ZipList(ListPack)是一种紧凑的列表结构,它通过连续存储元素来节约内存空间。当ZSet的元素数量增多时,Redis会自动将ZipList(ListPack)转换为SkipList,以保持元素的有序性和支持范围查询操作。
在这个过程中,Redis会遍历ZipList(ListPack)中的所有元素,按照元素的分数值依次将它们插入到SkipList中,这样就可以保持元素的有序性。
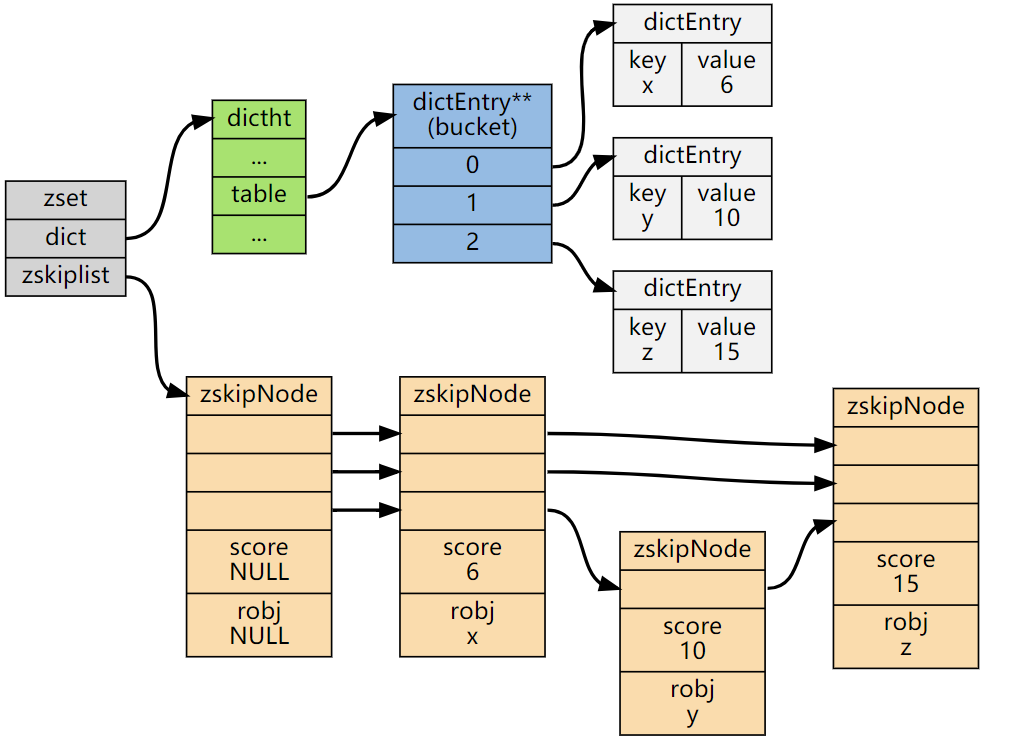
在Redis的ZSET具体实现中,SkipList的这种实现,不仅用到了跳表,还会用到dict(字典)
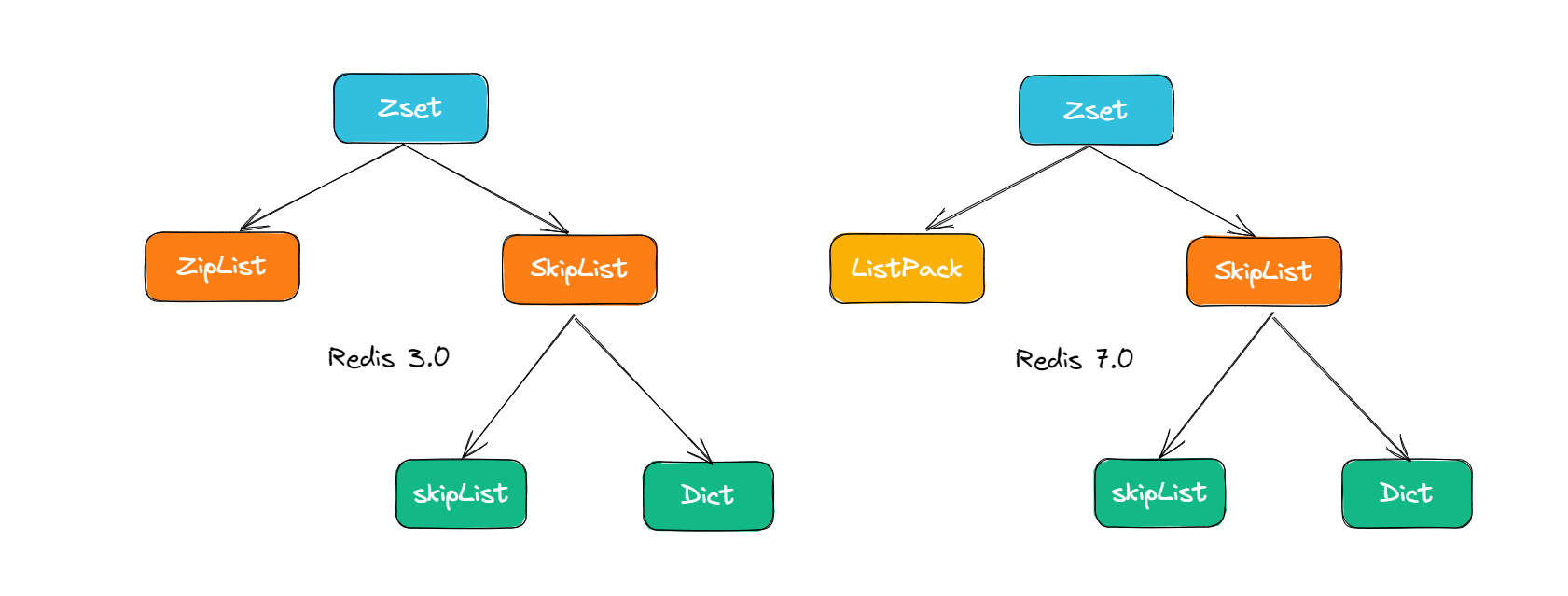
其中,SkipList用来实现有序集合,其中每个元素按照其分值大小在跳表中进行排序。跳表的插入、删除和查找操作的时间复杂度都是 O(log n),可以保证较好的性能。
dict用来实现元素到分值的映射关系,其中元素作为键,分值作为值。哈希表的插入、删除和查找操作的时间复杂度都是 O(1),具有非常高的性能。
扩展知识
何时转换
ZipList(ListPack)和SkipList之间是什么时候进行转换的呢?
在 Redis 中,ZSET在特定条件下会使用 ziplist作为其内部表示。这通常发生在有序集合较小的时候,具体条件如下:
- 元素数量少:集合中的元素数量必须小于某个阈值(zset-max-ziplist-entries)。
- 元素大小小:集合中的每个元素(包括值和分数)的大小必须小于指定的最大值(zset-max-ziplist-value)。
默认情况下,zset-max-ziplist-entries是128,zset-max-ziplist-value是64。
总的来说就是,当元素数量少于128,每个元素的长度都小于64字节的时候,使用ZipList(ListPack),否则,使用SkipList!
跳表
跳表也是一个有序链表,如下面这个数据结构:

在这个链表中,我们想要查找一个数,需要从头结点开始向后依次遍历和匹配,直到查到为止,这个过程是比较耗费时间的,他的时间复杂度是0(n)。
当我们想要向这个链表中插入一个数的时候,过程和查找类似,先需要从头开始遍历找到合适的为止,然后再插入,他的时间复杂度也是 O(n)。
那么,怎么能提升遍历速度呢,有一个办法,那就是我们对链表进行改造,先对链表中每两个节点建立第一级索引,如下图所示:

有了我们创建的这个索引之后,我们查询元素12,我们先从一级索引6 -> 9 -> 17 -> 26中查找,发现12介于9和17之间,然后,转移到下一层进行搜索,即9 -> 12 -> 17,即可找到12这个节点了。
可以看到,同样是查找12,原来的链表需要遍历5个元素(3、6、7、9、12),建立了一层索引之后,只需要遍历4个元素即可(6、9、17、12)。
像上面这种带多级索引的链表,就是跳表。