
- 首页
- 上一级
- A,B,C的联合索引,按照AB,AC,BC查询,能走索引吗?.md
- InnoDB中的索引类型?.md
- InnoDB中的表级锁、页级锁、行级锁?.md
- InnoDB为什么使用B+树实现索引?.md
- InnoDB和MyISAM有什么区别?.md
- InnoDB如何解决脏读、不可重复读和幻读的?.md
- InnoDB支持哪几种行格式?.md
- InnoDB的一次更新事务是怎么实现的?.md
- Innodb加索引,这个时候会锁表吗?.md
- Innodb的RR到底有没有解决幻读?.md
- MyISAM的索引结构是怎么样的,它存在的问题是什么?.md
- MySQL5.x和8.0有什么区别?.md
- MySQL中like的模糊查询如何优化.md
- MySQL中如何查看一个SQL的执行耗时.md
- MySQL中的事务隔离级别?.md
- MySQL为什么会有存储碎片?有什么危害?.md
- MySQL为什么是小表驱动大表,为什么能提高查询性能?.md
- MySQL主从复制的过程.md
- MySQL只操作同一条记录,也会发生死锁吗?.md
- MySQL怎么做热点数据高效更新?.md
- MySQL执行大事务会存在什么问题?.md
- MySQL是AP的还是CP的系统?.md
- MySQL是如何保证唯一性索引的唯一性的?.md
- MySQL用了函数一定会索引失效吗?.md
- MySQL的BLOB和TEXT有什么区别_.md
- MySQL的HashJoin是什么?.md
- MySQL的binlog有几种格式.md
- MySQL的limit+orderby为什么会数据重复?.md
- MySQL的select_会用到事务吗?.md
- MySQL的主键一定是自增的吗?.md
- MySQL的优化器的索引成本是怎么算出来的?.md
- MySQL的并行复制原理.md
- MySQL的数据存储一定是基于硬盘的吗?.md
- MySQL的深度分页如何优化.md
- MySQL的行级锁锁的到底是什么?.md
- MySQL的驱动表是什么?MySQL怎么选的?.md
- MySQL索引一定遵循最左前缀匹配吗?.md
- MySQL自增主键用完了会怎么样?.md
- MySQL获取主键id的瓶颈在哪里?如何优化?.md
- SQL中PK、UK、CK、FK、DF是什么意思?.md
- SQL执行计划分析的时候,要关注哪些信息?.md
- SQL语句如何实现insertOrUpdate的功能?.md
- Usingfilesort能优化吗,怎么优化?.md
- a,b两个单独索引,wherea=xxandb=xx走哪个索引?为什么?.md
- binlog、redolog和undolog区别?.md
- bufferpool的读写过程是怎么样的?.md
- char和varchar的区别?.md
- count(1)、count(_)与count(列名)的区别.md
- limit0,100和limit10000000,100一样吗?.md
- on和where有什么区别?.md
- orderby是怎么实现的?.md
- truncate、delete、drop的区别?.md
- undolog会一直存在吗?什么时候删除?.md
- uuid和自增id做主键哪个好,为什么?.md
- where条件的顺序影响使用索引吗?.md
- 一个查询语句的执行顺序是怎么样的?.md
- 为什么MySQL8.0要取消查询缓存?.md
- 为什么MySQL会选错索引,如何解决?.md
- 为什么MySQL默认使用RR隔离级别?.md
- 为什么不建议使用存储过程?.md
- 为什么不推荐使用外键?.md
- 为什么大厂不建议使用多表join?.md
- 为什么默认RR,大厂要改成RC?.md
- 乐观锁与悲观锁如何实现?.md
- 二级索引在索引覆盖时如何使用MVCC?.md
- 什么情况会导致自增主键不连续?.md
- 什么时候索引失效反而提升效率?.md
- 什么是InnoDB的页分裂和页合并.md
- 什么是MySQL的字典锁?.md
- 什么是OnlineDDL.md
- 什么是ReadView,什么样的ReadView可见?.md
- 什么是bufferpool?.md
- 什么是事务的2阶段提交?.md
- 什么是回表,怎么减少回表的次数?.md
- 什么是意向锁?.md
- 什么是排他锁和共享锁?.md
- 什么是数据库事务?.md
- 什么是数据库的主从延迟,如何解决?.md
- 什么是数据库的锁升级,Innodb支持吗?.md
- 什么是数据库范式,为什么要反范式?.md
- 什么是最左前缀匹配?为什么要遵守?.md
- 什么是索引合并,原理是什么?.md
- 什么是索引覆盖、索引下推?.md
- 什么是索引跳跃扫描.md
- 什么是聚簇索引和非聚簇索引?.md
- 什么是脏读、幻读、不可重复读?.md
- 介绍一下InnoDB的数据页,和B+树的关系是什么?.md
- 介绍下InnoDB的锁机制?.md
- 介绍下MySQL5.7中的组提交.md
- 从innodb的索引结构分析,为什么索引的key长度不能太长_.md
- 区分度不高的字段建索引一定没用吗?.md
- 唯一索引和主键索引的区别?.md
- 如何优化一个大规模的数据库系统?.md
- 如何理解MVCC?.md
- 如何进行SQL调优?.md
- 当前读和快照读有什么区别?.md
- 怎么比较两个索引的好坏?.md
- 慢SQL的问题如何排查?.md
- 执行计划中,key有值,还是很慢怎么办?.md
- 数据库乐观锁的过程中,完全没有加任何锁吗?.md
- 数据库加密后怎么做模糊查询?.md
- 数据库怎么做加密和解密?.md
- 数据库扫表任务如何避免出现死循环.md
- 数据库死锁如何解决?.md
- 是否支持emoji表情存储,如果不支持,如何操作?.md
- 有了关系型数据库,为什么还需要NOSQL?.md
- 用了索引还是很慢,可能是什么原因?.md
- 索引失效的问题如何排查?.md
- 联合索引是越多越好吗?.md
- 设计索引的时候有哪些原则?.md
- 说一说MySQL一条SQL语句的执行过程?.md
- 阿里的数据库能抗秒杀的原理.md
- 高并发情况下自增主键会不会重复,为什么?.md
✅InnoDB为什么使用B+树实现索引?
典型回答
首先看看B+树有哪些特点:
- B+树是一棵平衡树,每个叶子节点到根节点的路径长度相同,查找效率较高;
- B+树的所有关键字都在叶子节点上,因此范围查询时只需要遍历一遍叶子节点即可;
- B+树的叶子节点都按照关键字大小顺序存放,因此可以快速地支持按照关键字大小进行排序;
- B+树的非叶子节点不存储实际数据,因此可以存储更多的索引数据;
- B+树的非叶子节点使用指针连接子节点,因此可以快速地支持范围查询和倒序查询。
- B+树的叶子节点之间通过双向链表链接,方便进行范围查询。
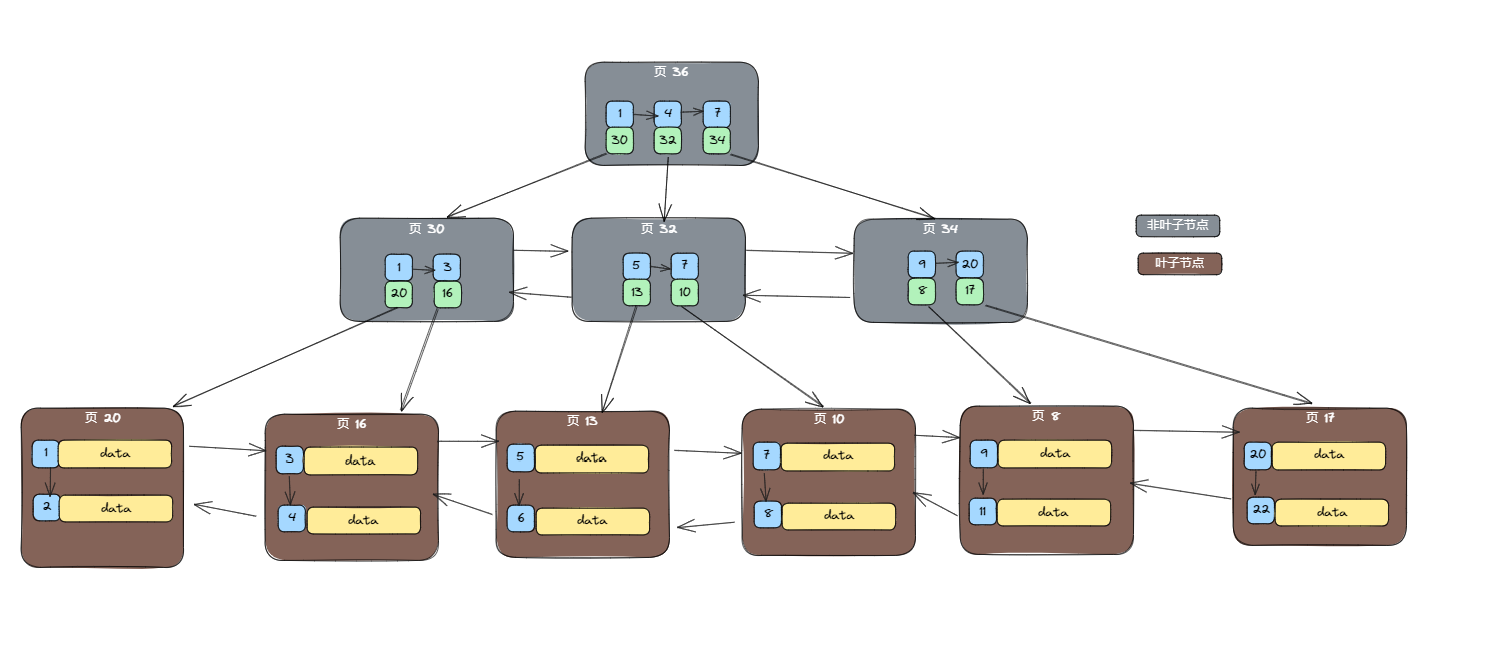
那么,使用B+树实现索引,就有以下几个优点:
- 支持范围查询,B+树在进行范围查找时,只需要从根节点一直遍历到叶子节点,因为数据都存储在叶子节点上,而且叶子节点之间有指针连接,可以很方便地进行范围查找。
- 支持排序,B+树的叶子节点按照关键字顺序存储,可以快速支持排序操作,提高排序效率;
- 存储更多的索引数据,因为它的非叶子节点只存储索引关键字,不存储实际数据,因此可以存储更多的索引数据;
- 在节点分裂和合并时,IO操作少。B+树的叶子节点的大小是固定的,而且节点的大小一般都会设置为一页的大小,这就使得节点分裂和合并时,IO操作很少,只需读取和写入一页。
- 有利于磁盘预读。由于B+树的节点大小是固定的,因此可以很好地利用磁盘预读特性,一次性读取多个节点到内存中,这样可以减少IO操作次数,提高查询效率。
- 有利于缓存。B+树的非叶子节点只存储指向子节点的指针,而不存储数据,这样可以使得缓存能够容纳更多的索引数据,从而提高缓存的命中率,加快查询速度。
扩展知识
为什么不用红黑树或者B树?
因为B+树的特点是只有叶子节点存储数据,而非叶子节点不存储数据,并且节点大小固定,还有就是叶子结点之间通过双向链表链接的,所以,使用B+树实现索引有很多好处,比如我们前面提到的支持范围查询、有利于磁盘预读、有利于优化排序等等。而这些是红黑树和B树做不到的。
B+树索引和Hash索引有什么区别?
B+ 树索引和哈希索引是常见的数据库索引结构,它们有以下几个主要区别:
B+ 树索引将索引列的值按照大小排序后存储,因此B+ 树索引适合于范围查找和排序操作;而哈希索引是将索引列的值通过哈希函数计算后得到一个桶的编号,然后将桶内的记录保存在一个链表或者树结构中。因此,哈希索引适合于等值查询,但不适合范围查询和排序操作。
B+ 树索引在插入和删除数据时需要调整索引结构,这个过程可能会涉及到页分裂和页合并等操作,因此B+ 树索引的维护成本比较高;而哈希索引在插入和删除数据时只需要计算哈希值并插入或删除链表中的记录,因此哈希索引的维护成本相对较低。
B+ 树索引在磁盘上是有序存储的,因此在进行区间查询时可以利用磁盘预读的优势提高查询效率;而哈希索引在磁盘上是无序存储的,因此在进行区间查询时可能会需要随机访问磁盘,导致查询效率降低。
B+ 树索引在节点中存储多个键值对,因此可以充分利用磁盘块的空间,提高空间利用率;而哈希索引由于需要存储哈希值和指针,因此空间利用率相对较低。