
- 首页
- 上一级
- A,B,C的联合索引,按照AB,AC,BC查询,能走索引吗?.md
- InnoDB中的索引类型?.md
- InnoDB中的表级锁、页级锁、行级锁?.md
- InnoDB为什么使用B+树实现索引?.md
- InnoDB和MyISAM有什么区别?.md
- InnoDB如何解决脏读、不可重复读和幻读的?.md
- InnoDB支持哪几种行格式?.md
- InnoDB的一次更新事务是怎么实现的?.md
- Innodb加索引,这个时候会锁表吗?.md
- Innodb的RR到底有没有解决幻读?.md
- MyISAM的索引结构是怎么样的,它存在的问题是什么?.md
- MySQL5.x和8.0有什么区别?.md
- MySQL中like的模糊查询如何优化.md
- MySQL中如何查看一个SQL的执行耗时.md
- MySQL中的事务隔离级别?.md
- MySQL为什么会有存储碎片?有什么危害?.md
- MySQL为什么是小表驱动大表,为什么能提高查询性能?.md
- MySQL主从复制的过程.md
- MySQL只操作同一条记录,也会发生死锁吗?.md
- MySQL怎么做热点数据高效更新?.md
- MySQL执行大事务会存在什么问题?.md
- MySQL是AP的还是CP的系统?.md
- MySQL是如何保证唯一性索引的唯一性的?.md
- MySQL用了函数一定会索引失效吗?.md
- MySQL的BLOB和TEXT有什么区别_.md
- MySQL的HashJoin是什么?.md
- MySQL的binlog有几种格式.md
- MySQL的limit+orderby为什么会数据重复?.md
- MySQL的select_会用到事务吗?.md
- MySQL的主键一定是自增的吗?.md
- MySQL的优化器的索引成本是怎么算出来的?.md
- MySQL的并行复制原理.md
- MySQL的数据存储一定是基于硬盘的吗?.md
- MySQL的深度分页如何优化.md
- MySQL的行级锁锁的到底是什么?.md
- MySQL的驱动表是什么?MySQL怎么选的?.md
- MySQL索引一定遵循最左前缀匹配吗?.md
- MySQL自增主键用完了会怎么样?.md
- MySQL获取主键id的瓶颈在哪里?如何优化?.md
- SQL中PK、UK、CK、FK、DF是什么意思?.md
- SQL执行计划分析的时候,要关注哪些信息?.md
- SQL语句如何实现insertOrUpdate的功能?.md
- Usingfilesort能优化吗,怎么优化?.md
- a,b两个单独索引,wherea=xxandb=xx走哪个索引?为什么?.md
- binlog、redolog和undolog区别?.md
- bufferpool的读写过程是怎么样的?.md
- char和varchar的区别?.md
- count(1)、count(_)与count(列名)的区别.md
- limit0,100和limit10000000,100一样吗?.md
- on和where有什么区别?.md
- orderby是怎么实现的?.md
- truncate、delete、drop的区别?.md
- undolog会一直存在吗?什么时候删除?.md
- uuid和自增id做主键哪个好,为什么?.md
- where条件的顺序影响使用索引吗?.md
- 一个查询语句的执行顺序是怎么样的?.md
- 为什么MySQL8.0要取消查询缓存?.md
- 为什么MySQL会选错索引,如何解决?.md
- 为什么MySQL默认使用RR隔离级别?.md
- 为什么不建议使用存储过程?.md
- 为什么不推荐使用外键?.md
- 为什么大厂不建议使用多表join?.md
- 为什么默认RR,大厂要改成RC?.md
- 乐观锁与悲观锁如何实现?.md
- 二级索引在索引覆盖时如何使用MVCC?.md
- 什么情况会导致自增主键不连续?.md
- 什么时候索引失效反而提升效率?.md
- 什么是InnoDB的页分裂和页合并.md
- 什么是MySQL的字典锁?.md
- 什么是OnlineDDL.md
- 什么是ReadView,什么样的ReadView可见?.md
- 什么是bufferpool?.md
- 什么是事务的2阶段提交?.md
- 什么是回表,怎么减少回表的次数?.md
- 什么是意向锁?.md
- 什么是排他锁和共享锁?.md
- 什么是数据库事务?.md
- 什么是数据库的主从延迟,如何解决?.md
- 什么是数据库的锁升级,Innodb支持吗?.md
- 什么是数据库范式,为什么要反范式?.md
- 什么是最左前缀匹配?为什么要遵守?.md
- 什么是索引合并,原理是什么?.md
- 什么是索引覆盖、索引下推?.md
- 什么是索引跳跃扫描.md
- 什么是聚簇索引和非聚簇索引?.md
- 什么是脏读、幻读、不可重复读?.md
- 介绍一下InnoDB的数据页,和B+树的关系是什么?.md
- 介绍下InnoDB的锁机制?.md
- 介绍下MySQL5.7中的组提交.md
- 从innodb的索引结构分析,为什么索引的key长度不能太长_.md
- 区分度不高的字段建索引一定没用吗?.md
- 唯一索引和主键索引的区别?.md
- 如何优化一个大规模的数据库系统?.md
- 如何理解MVCC?.md
- 如何进行SQL调优?.md
- 当前读和快照读有什么区别?.md
- 怎么比较两个索引的好坏?.md
- 慢SQL的问题如何排查?.md
- 执行计划中,key有值,还是很慢怎么办?.md
- 数据库乐观锁的过程中,完全没有加任何锁吗?.md
- 数据库加密后怎么做模糊查询?.md
- 数据库怎么做加密和解密?.md
- 数据库扫表任务如何避免出现死循环.md
- 数据库死锁如何解决?.md
- 是否支持emoji表情存储,如果不支持,如何操作?.md
- 有了关系型数据库,为什么还需要NOSQL?.md
- 用了索引还是很慢,可能是什么原因?.md
- 索引失效的问题如何排查?.md
- 联合索引是越多越好吗?.md
- 设计索引的时候有哪些原则?.md
- 说一说MySQL一条SQL语句的执行过程?.md
- 阿里的数据库能抗秒杀的原理.md
- 高并发情况下自增主键会不会重复,为什么?.md
✅MySQL的Hash Join是什么?
典型回答
hash join 是 MySQL 8.0.18版本中新推出的一种多表join的算法。
在这之前,MySQL是使用了嵌套循环(Nested-Loop Join)的方式来实现关联查询的,而嵌套循环的算法其实性能是比较差的,而Hash Join的出现就是要优化Nested-Loop Join的。
所谓Hash Join,其实是因为他底层用到了Hash表。
Hash Join 是一种针对 equal-join 场景的优化,他的基本思想是将驱动表数据加载到内存,并建立 hash 表,这样只要遍历一遍非驱动表,然后再去通过哈希查找在哈希表中寻找匹配的行 ,就可以完成 join 操作了。
举个栗子。
SELECT
student_name,school_name
FROM
students LEFT JOIN schools ON students.school_id=schools.id;
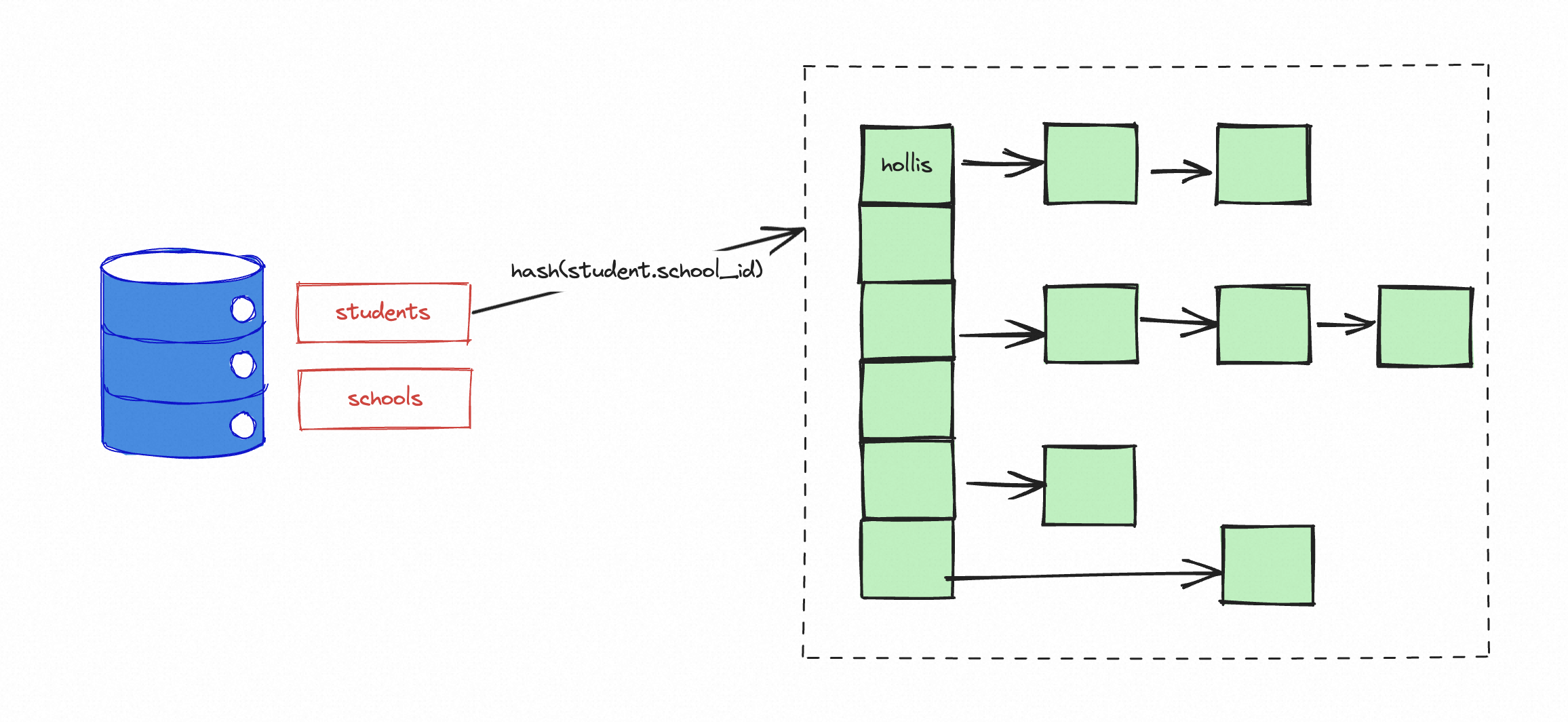
以上,是一个left join的SQL,在Hash Join过程中,主要分为两个步骤,分别是构建和探测。
构建阶段,假如优化器优化后使用students作为驱动表,那么就会把这个驱动表的数据构建到hash表中:
探测阶段,在这个过程中,从school表中取出记录之后,去hash表中查询,找到匹配的数据,在做聚合就行了。
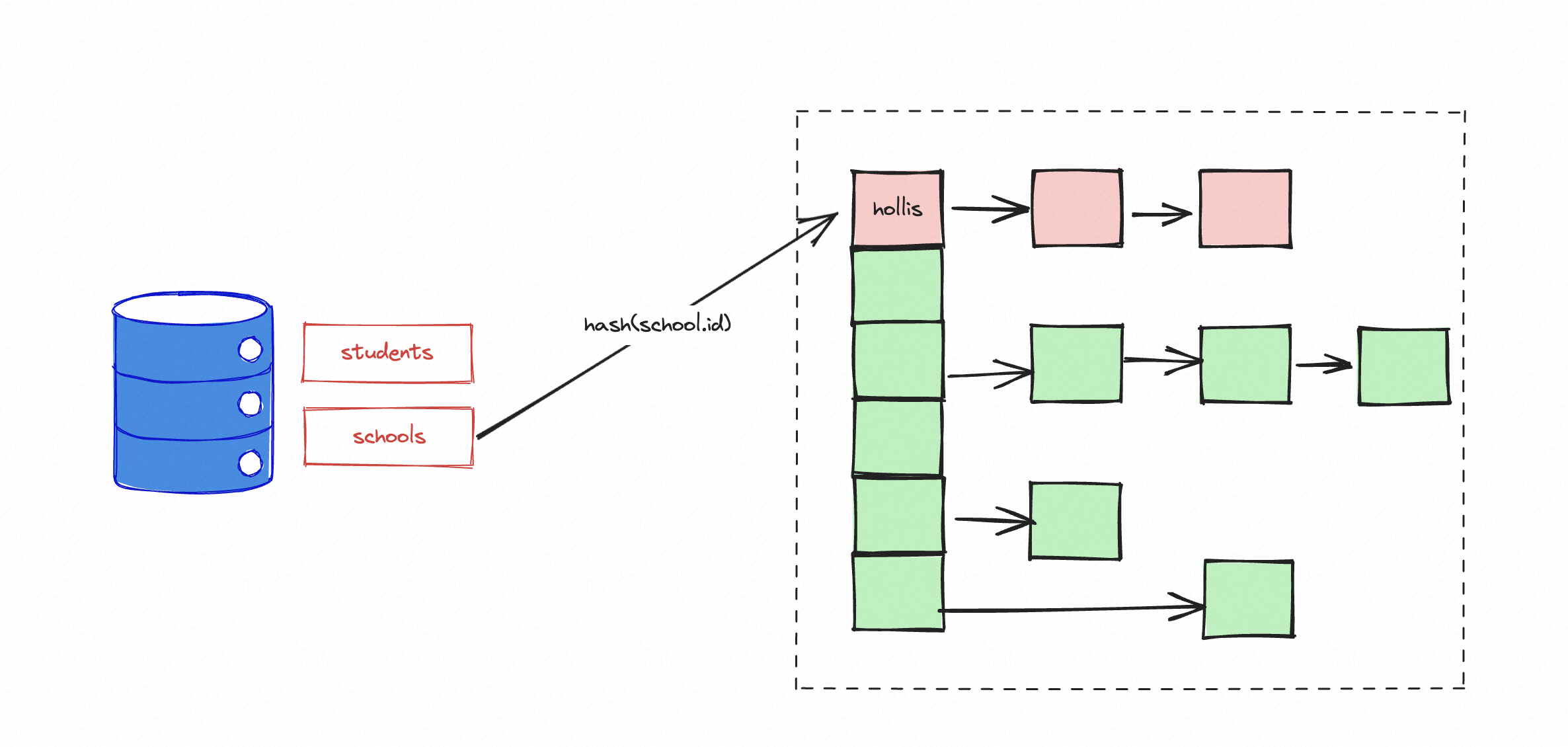
需要注意的时候,上面的Hash表是在内存中的,但是,内存是有限的(通过joinbuffersize限制),如果内存中存不下驱动表的数据怎么办呢?
扩展知识
基于磁盘的hash join
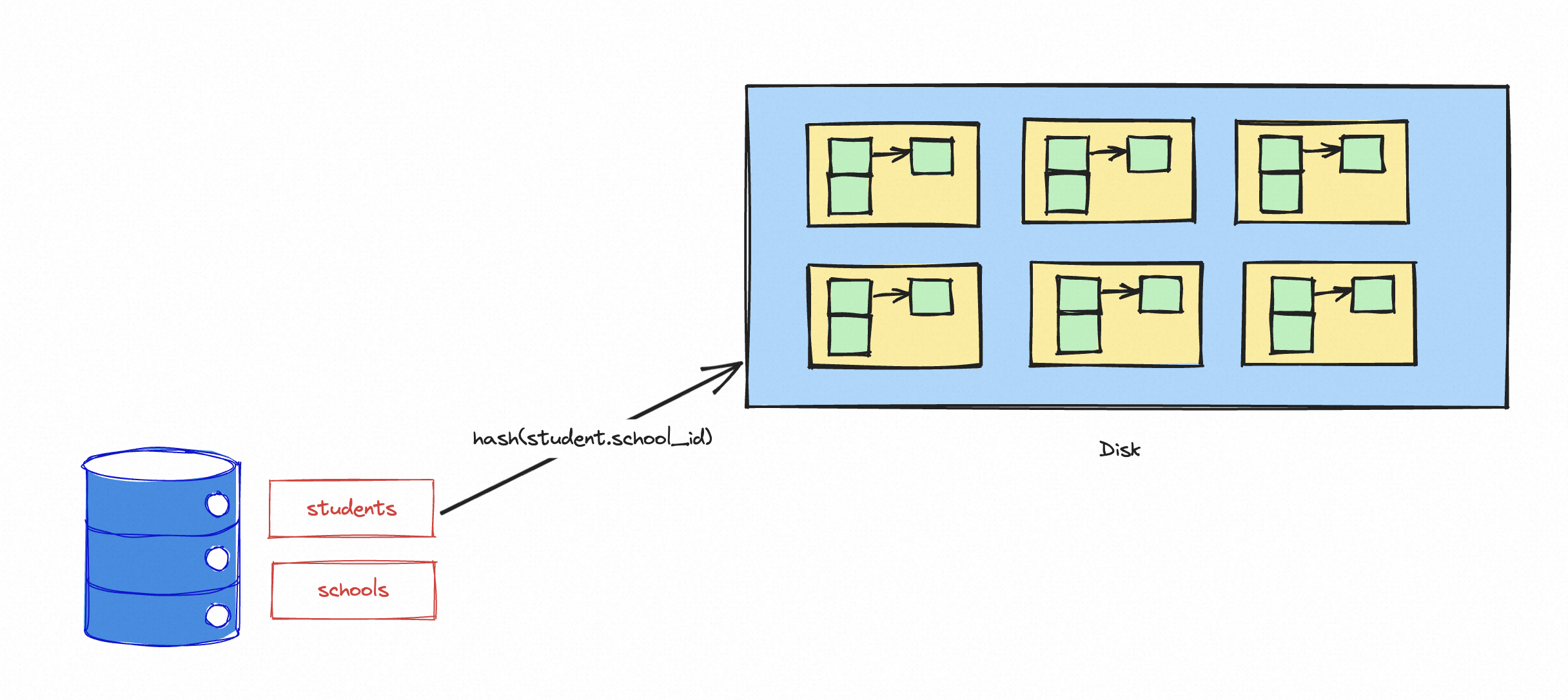
如果驱动表中的数据量比较大, 没办法一次性的加载到内存中,就需要考虑把这些数据存储在磁盘上。通过将哈希表的一部分存储在磁盘上,分批次地加载和处理数据,从而减少对内存的需求。
在这样的算法中,为了避免一个大的hash表内存中无法完全存储,那么就采用分表的方式来实现,即首先利用 hash 算法将驱动表进行分表,并产生临时分片写到磁盘上。
这样就相当于把一张驱动表,拆分成多个hash表,并且分别存储在磁盘上。
接下来就是做join了,在这个过程中,会对被驱动表使用同样的 hash 算法进行分区,确定好在哪个分区之后,先确认下这个分区是否已经加载到内存,如果已经加载,则直接在内存中的哈希表中进行查找匹配的行。
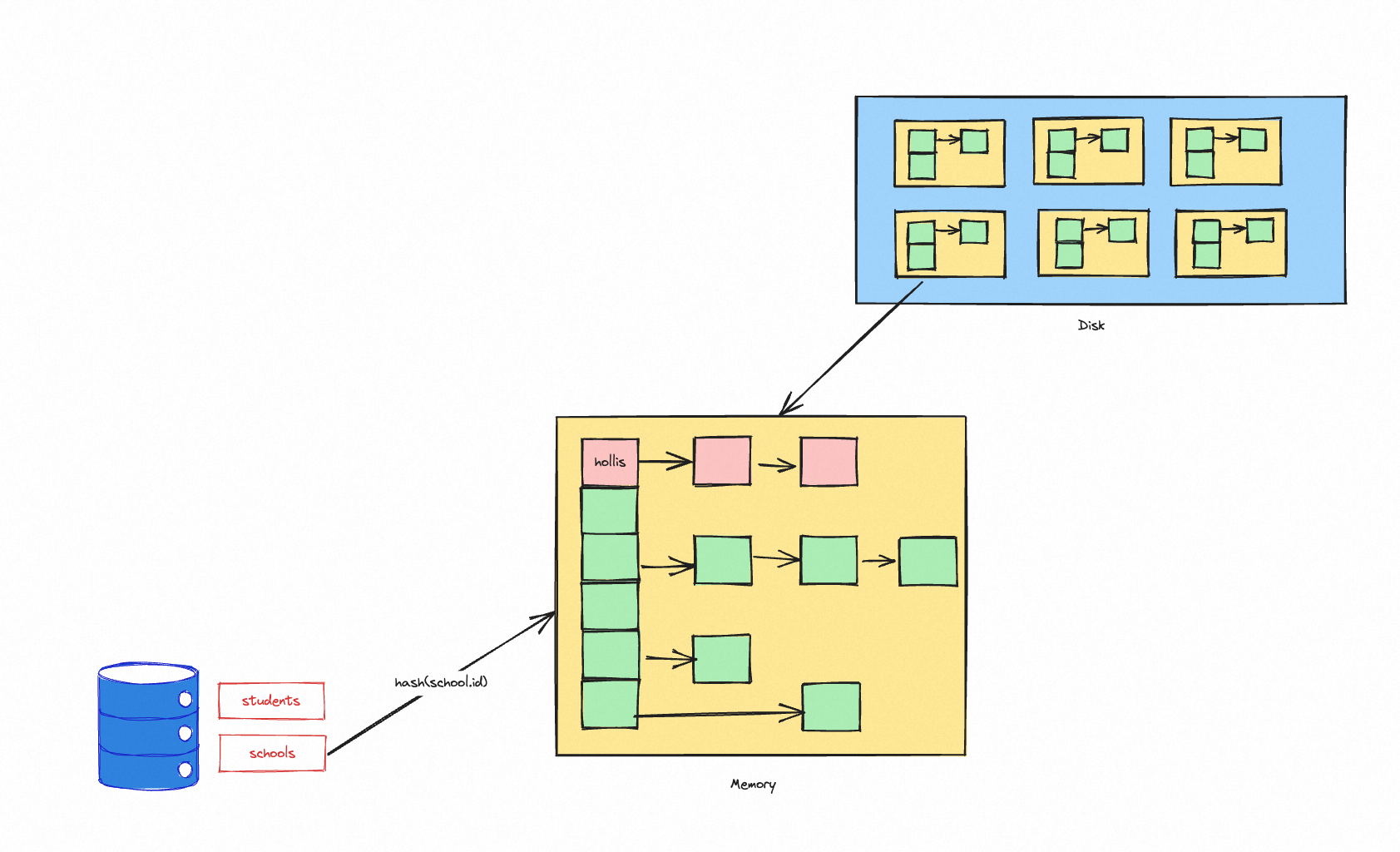
如果哈希值对应的分区尚未加载到内存中,则从磁盘上读取该分区的数据到内存中的哈希表,并进行匹配。
就这样不断的重复进行下去,直到把所有数据都join完,把结果集返回。